Lifecycle of an Utterance
How every user request is handled and the policies and safeguards in the Copilot
This covers Moveworks CopilotMoveworks Copilot is the latest conversational experience
Generative AI in the Copilot
The Moveworks Copilot employs several generative Large Language Models, most notably, GPT-4o to perform a number of language and reasoning tasks, resulting in an autonomous, natural conversational experience. In this article, we will dive deeper into the lifecycle of an utterance in the Copilot and the steps taken to make sure that users have a safe and delightful interaction every time.
Note that the generative aspect of the LLMs is fully woven into this experience and has been integrated into your Moveworks bot to work seamlessly with your systems and business rules.
Guiding Principles of the Copilot
Every request to the the Moveworks Copilot passes through a series of stages to find the most helpful responses for the user. The Copilot uses a combination of natural language understanding, reasoning and the available plugins in the customer’s environment to serve a wide variety of user requests.
The following guiding principles inform how requests are processed and responses are served:
- Ensure that toxic, inappropriate or offensive content does not enter the system.
- Be cautious with sensitive and highly subjective topics
- As far as possible, use available plugins as tools to serve user requests. Do not respond to the user without attempting to use plugins first.
- As far as possible, respond to users with relevant content from their organization’s resources.
- Within these constraints, try to be helpful to the user as a friendly, enterprise Copilot.
- Give users visibility into the content used to generate the responses.
Input safeguards and checks
There are two main checks that are in place to make sure that inappropriate content is prevented from being processed. This ensures that the Copilot is available to help with work and productivity-related requests, but does not engage with users on topics or requests that are toxic, offensive or controversial.
Toxicity Filter
Purpose: Block inappropriate content and requests from entering the system.
How it works: Using machine learning, all incoming requests are analyzed for potential toxic or non-work appropriate content. Moveworks supplements GPT’s own toxicity check with a fine-tuned large language model (FLAN-T5) that assesses appropriateness for work environments, and uses a policy that guides the Moveworks Copilot to not engage with the user if such a request is detected. In cases where the toxicity filter is triggered, the user will receive a message similar to I'm unable to assist with that request, and will not receive an acknowledgement of the issue.
Examples: Language that is hateful, abusive, derogatory or offensive.
Sensitive Topics Policy
Purpose: Instruct the Moveworks Copilot to not engage the user on topics that are sensitive and may be considered highly subjective from one person to another. The goal is to set expectations with users that the Moveworks Copilot is not the right medium to discuss these topics.
How it works: Using policies which are applied to all requests, Moveworks instructs the GPT-4 model to analyze the theme of the request and decline to discuss potentially sensitive topics such as those related to medical, psychological, physiological, emotional, financial or political matters. These are treated differently from content that is considered toxic, and the user may receive an acknowledgement and polite refusal to respond.
Understanding and Reasoning
In the following steps the Copilot processes all utterances that pass the input checks and extracts important information about them. It then proceeds to devise a plan to address the request using the plugins available in the customer's environment.
Dialogue Analysis
In this stage, the Moveworks Copilot determines fundamental characteristics of the request such as the language of the utterance, domain of the request, user intent, whether the request is a continuation of the previous request, and whether the request is toxic or inappropriate. If the request can be served, the Moveworks Copilot also identifies entities in the request and attempts to link them to known entities in Moveworks’ entity database. The query may also be rewritten or rephrased to incorporate contextual references from previous interactions.
The output of this step is an expanded understanding of the request and how it fits within the ongoing conversation between the user and the Moveworks Copilot.
Planning
With the information from dialogue analysis, the Moveworks Copilot’s reasoning engine, powered by GPT-4o, reviews the previous conversation history and determines what to do next and what to communicate to the user. In this stage, the Moveworks Copilot also incorporates relevant customer-specific business rules and overrides as it decides its next step.
If a step has already been taken, then the Moveworks Copilot also reviews the output of that previous step and decides whether to try a different approach or continue with the current strategy of solving the request.
Plugin Selection
An important part of planning that deserves to be called out separately is plugin selection. Here, the Moveworks Copilot tries to match the user request with the best plugin from the list of all available plugins in the customer’s environment (including custom plugins built using Agent Studio) by using their descriptions and the arguments they take as inputs.
Currently, the Moveworks Copilot tries to select the single most useful plugin for every request at a time.
Plugin Execution
After the plugin is selected, the Moveworks Copilot sends the user’s request to it in the form required by that plugin to function. Plugins execute the request and respond back to the core reasoning engine with either a completed, successful response, or with an error, or a request for more information from the user to complete the execution of the task.
Plan Evaluation
Based on the response from the plugin, the reasoning engine determines what to do next. This stage is essentially the same as the planning step above, if an utterance is currently being processed.
Response Generation
Depending on the plan evaluation, the Moveworks Copilot then produces a response for the user that may have the answer to the question, an update on further processing, or a request for clarification or disambiguation. In each of these cases, the Copilot compiles a response that directly addresses the user's query, taking into account the previous conversation context.
This step combines two key capabilities of large language models - reasoning and text generation, and gives the output its characteristic natural tone and fluidity.
Fallback scenarios
In some cases, the user's request cannot be served by any plugins because there may either be no knowledge or no automations to address it. In such cases, the Copilot may produce one of the following responses:
- It will inform the user that based on its search and plugin analysis, there is no available information. However, the user may click on "Get Help" to view options to receive assistance.
- It may offer the option to the user to file a ticket in chat itself, if it determines that this type of request could be addressed by a human agent.
- For requests that pass the conditions mentioned above, and if there are no plugins that can address the request, the Copilot may use its "world knowledge" or "memory" to provide a response to the user. In general, requests that are direct and creative in nature may be served with such a response. This is rare when the user asks about something that is technical or work-related in nature, and may be better served by leveraging authoritative knowledge.
- Note that no internet search is done for this type of response and there are no citations available, which makes it clear to the user that this response in not grounded in their organization's knowledge. This is a key transparency feature. See more about this in our section on Helpfulness as an Enterprise Assistant.
Output Safeguards
Toxicity Filter
Similar to the toxicity checks on the input side, we also check the generated output to ensure that it is appropriate for work environments. This provides an additional layer of protection against malicious attempts to bypass controls on the input side.
Citations
Purpose: While the Copilot provides a summarized response in chat, it shows all citations - indicated by a superscript number (e.g., (1) - from the source. Citations allow users to read the source article and verify the truthfulness of the Copilot response.
How they work: Citations can be a knowledge article snippet, a person's profile card, an office map, or response from a Agent Studio API call. Users can access the citations by clicking on the ℹ️ icon at the bottom of each Copilot response. If a response has no citation, then it means that there is no available content to link from the customer's data.
Linked Verified Entities
Purpose: To provide validation of Copilot's summarized response against existing knowledge resources - what we call “grounding” - ensuring users can trust the information they receive from Copilot.
How they work: We verify entities mentioned in user messages through a two-step process:
- We predefine the types of entity mentions we want to verify (e.g., people, URLs).
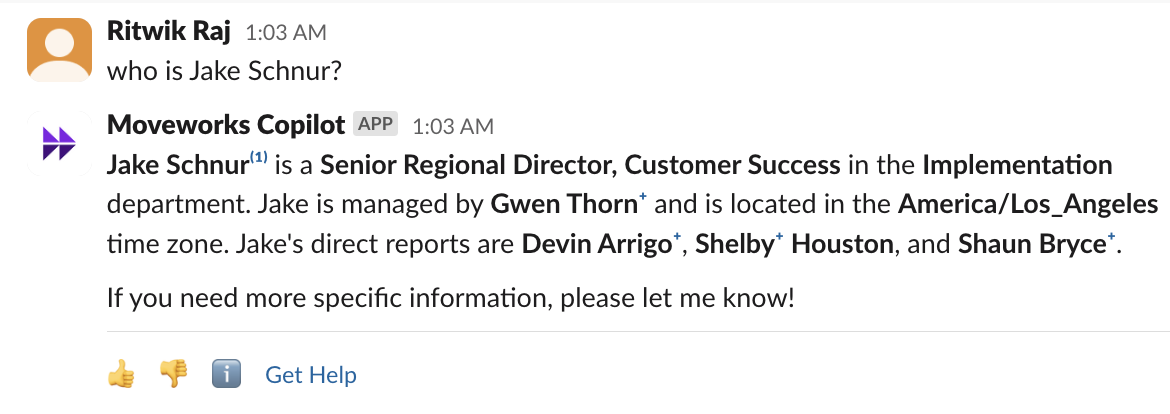
- We check each step of the plugin responses to ensure those mentions can be found in the source. If they are found, the entity is verified. Verified entities will be marked with a small “+” superscript. Clicking on the “+” will direct you to the reference section where the entity is verified.
Here's an example showing how the direct reports of Jake Schnur are verified with "+" as being found on Jake's employee lookup card:
Providing safe generative responses
As explained in the guiding principles above, Moveworks is committed to making sure that every user has a safe and helpful experience with the Copilot. See this section to learn about our efforts to provide accurate and reliable answers.
Note that Generative large language models such as GPT-4 and Llama 3 excel at producing natural, fluid text in response to requests. They owe their linguistic abilities to the huge amounts of data that they have been trained on. This data is embedded as a snapshot in the model once it has been trained, and does not depend on or require internet access to refresh or update. The only way to update this data snapshot inside the model is to retrain the model. The ability to generate high quality text “from memory” enables these LLMs to have rich conversations with users.
Responses without citations
A response without citations is called an ungrounded response. It’s important to note that currently, the Moveworks Copilot does not search the open internet. Therefore, if an answer has not been sourced from the available references, then there is a chance that it may be ungrounded. There are a couple of troubleshooting questions that can guide you towards more clarity within a few minutes:
- Were any Plugins called as part of the AI Reasoning? Check the AI Reasoning for the response. If no plugins were called, then the response was likely ungrounded.
- Are there no citations in the citations panel? If no citations, then this is the tell-tale sign of a ungrounded response. But if there are citations, the you can trace which pieces of content were used to generate the response.
See here to learn more about possible scenarios in which ungrounded responses may be observed.
How does the Moveworks Copilot learn and improve?
The Moveworks Copilot consists of a suite of machine learning models that are used for a variety of tasks such as reasoning and planning (GPT-4o), knowledge search, toxicity detection, language detection, resource translation and many others.
The Copilot is in continuous improvement with regular updates to not just ML models, but also user experience enhancements, architecture and infrastructure improvements.
This improvement happens mainly via two pathways:
- Review of subjective feedback: Moveworks annotation teams and ML engineers regularly review masked and anonymized usage data to identify themes for improvement. In addition, user feedback from MS Teams or Slack, customer feedback from support tickets and Community are also used to identify improvements to specific use cases.
- Targeted improvements to improve metrics: We closely monitor metrics such as latency, error rates and response rates, and prioritize investments to improve the platform across all sue cases.
Currently, there is no automated self-learning feedback loop in the Moveworks Copilot. Therefore, there are no automatic changes in behavior that occur solely based on providing feedback or from interactions between the user and the copilot. This means that the Copilot does not automatically adapt its behavior based on previous examples of similar interactions. However, we review randomly sampled usage data to identify key patterns and make continuous improvements for high frequency issues.
Updated about 2 months ago