Atlassian Confluence
Overview
With the Atlassian Confluence content connector, Moveworks Enterprise Search enables the Moveworks AI Assistant to answer user’s questions directly in chat, by understanding the questions and responding instantly with answers containing the most relevant content, links to knowledge base articles or files, or links to external articles taken from trusted knowledge sources.
Supported Confluence Versions
Moveworks supports the following versions of Confluence:
- Confluence Cloud
- Confluence On-Prem: Confluence Server & Datacenter
- Note: Confluence Server requires leveraging the Moveworks Agent to securely connect to your Confluence On-Prem.
Supported Content Types
Moveworks supports ingesting Confluence wiki articles, Pages, & Blog posts
WARNING: Moveworks does not ingest macros, native or 3rd-party.
How Moveworks Integrates with Confluence
Moveworks has Indexed Search support for Confluence and supports publicly available content within Confluence.
Confluence Advanced Features and Configurations
Moveworks offers two methods to filter Confluence wiki articles that will be leveraged by Moveworks.
Knowledge Ingestion Filtering Methods
Moveworks can be configured to filter the knowledge being ingested by Spaces or by a CQL query, typically from an ancestor page. Depending on what version of Confluence Server is supported in your system, the method of filtering knowledge ingestion will differ.
Method 1: Ingest by Spaces
In the majority of cases, Moveworks will import articles from Confluence by Space. For example, if you have a space called “IT Self Service”, Moveworks would ingest all published pages under that space.
To ingest articles by Space, Moveworks uses an API call leveraging the content endpoint like so: /wiki/rest/api/content?limit=25&status=current&spaceKey=IT%20Self%20Service .
Method 2: Ingest using Confluence Query Language (CQL)
In some cases, a given space may contain some pages should not be ingested. In this case, Moveworks can leverage the Confluence Query Language (CQL), which uses a SQL type syntax, for advanced search and filtering. One of the best parts about CQL is that it allows you to define more advanced search options such as cherry picking the content id of “ancestor” pages and recursively ingesting all the child KBs under that ancestor page.
To do this, Moveworks would use an API call that leverages the “search” endpoint to pass in a CQL query like so: rest/api/content/search?cql=ancestor=1234567859&limit=300&label="mw-inc”
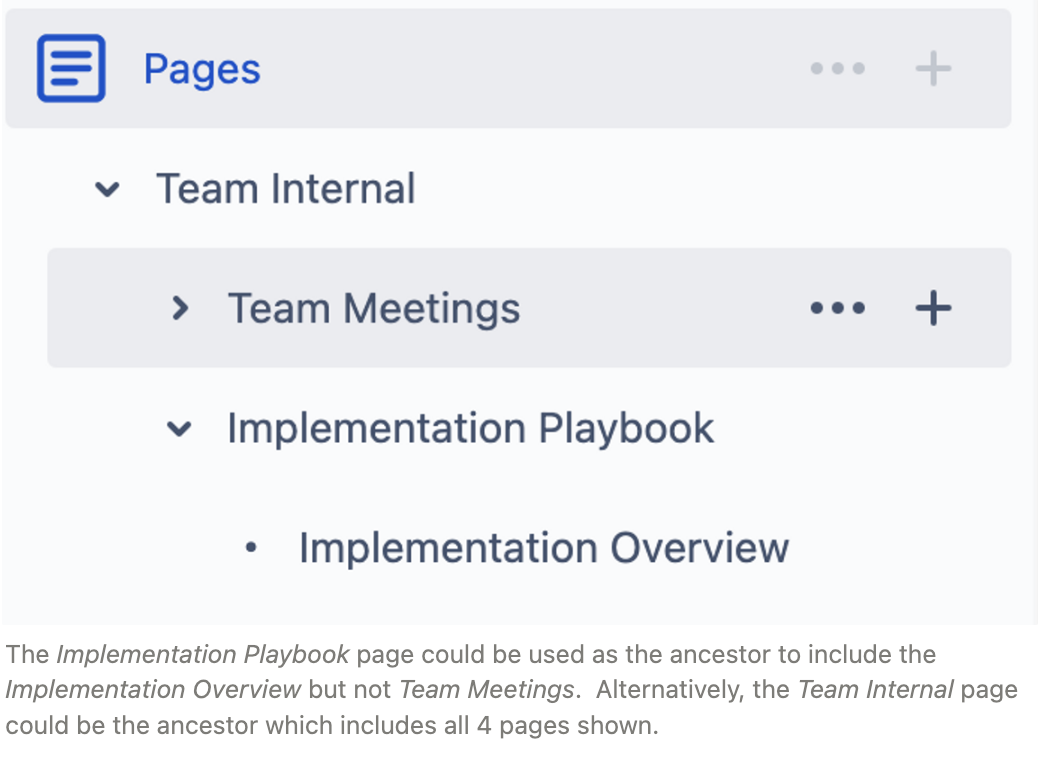
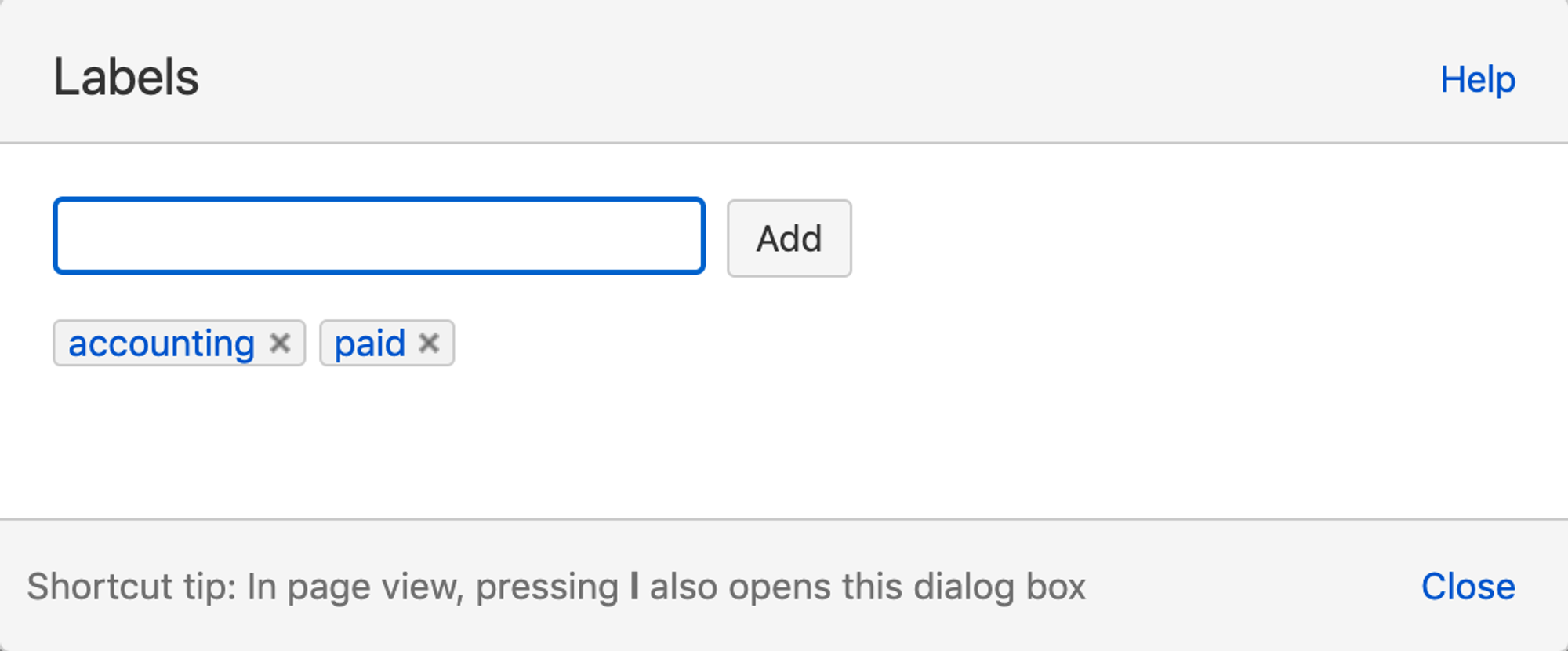
Another popular method of ingestion that leverages CQL is to ingest articles by labels. In Confluence, labels are key words that you can add to pages and attachments to make them easier to group and find. Labels are similar to tags, you can label an article moveworks and then in your Moveworks knowledge ingestion configuration you could use a CQL query like: label = moveworks AND space = IT
Functionalities
Search
By integrating Moveworks with Confluence you can search for the most relevant answers to your user’s questions within Confluence wiki articles, pages, blog posts. See our guide on Answers to learn more.
Updated 8 months ago