How to Configure Fresh Desk Knowledge Ingestion
Pre-Requisites
- Please ensure the required Fresh Desk Connector has been created with the necessary permissions. Please refer the Fresh Desk Access Requirements Doc for details. The Document will also walk you through the steps for creating the Connector.
- Please ensure the API Key being used for connecting to Fresh Desk has access to the necessary scopes.
Configuration
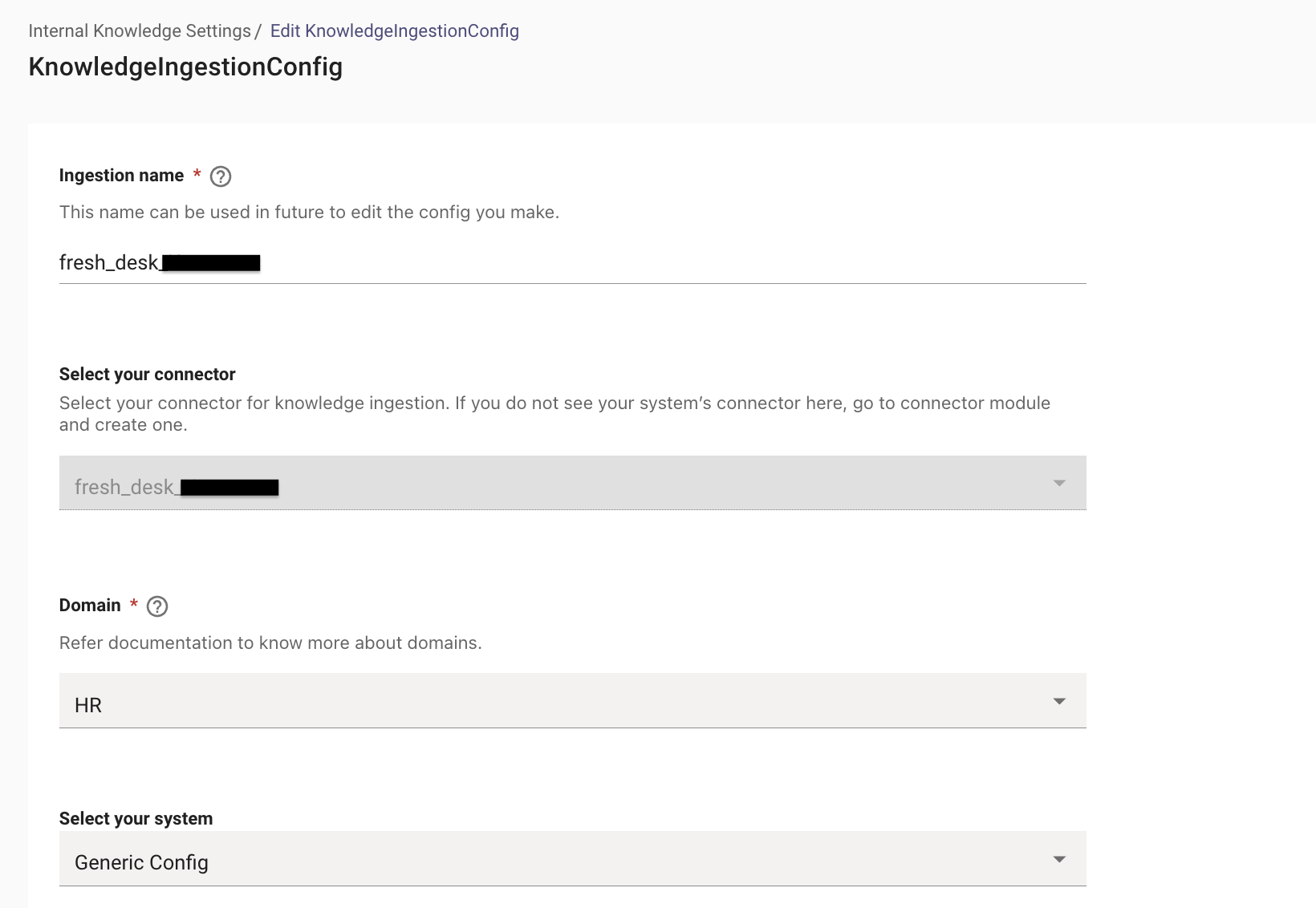
Start by creating a new Ingestion under Answers > Ingestion > Internal Knowledge Settings
-
First, select the Connector created for the ingestion and then provide a name for the ingestion. under Ingestion Name.
-
Then, choose a Domain. The domain is the functional areas of employee service that is most related to the knowledge being ingested for this configuration.
Setup Knowledge Bases in Advanced Mode
-
In the Advanced mode, in order to ingest articles from a folder belonging to a specific group, we need to select Select the System as Generic Config.
-
The Generic Config allows us to ingest content from an API response, this is done by mapping the Response to the Moveworks Internal Attributes.
-
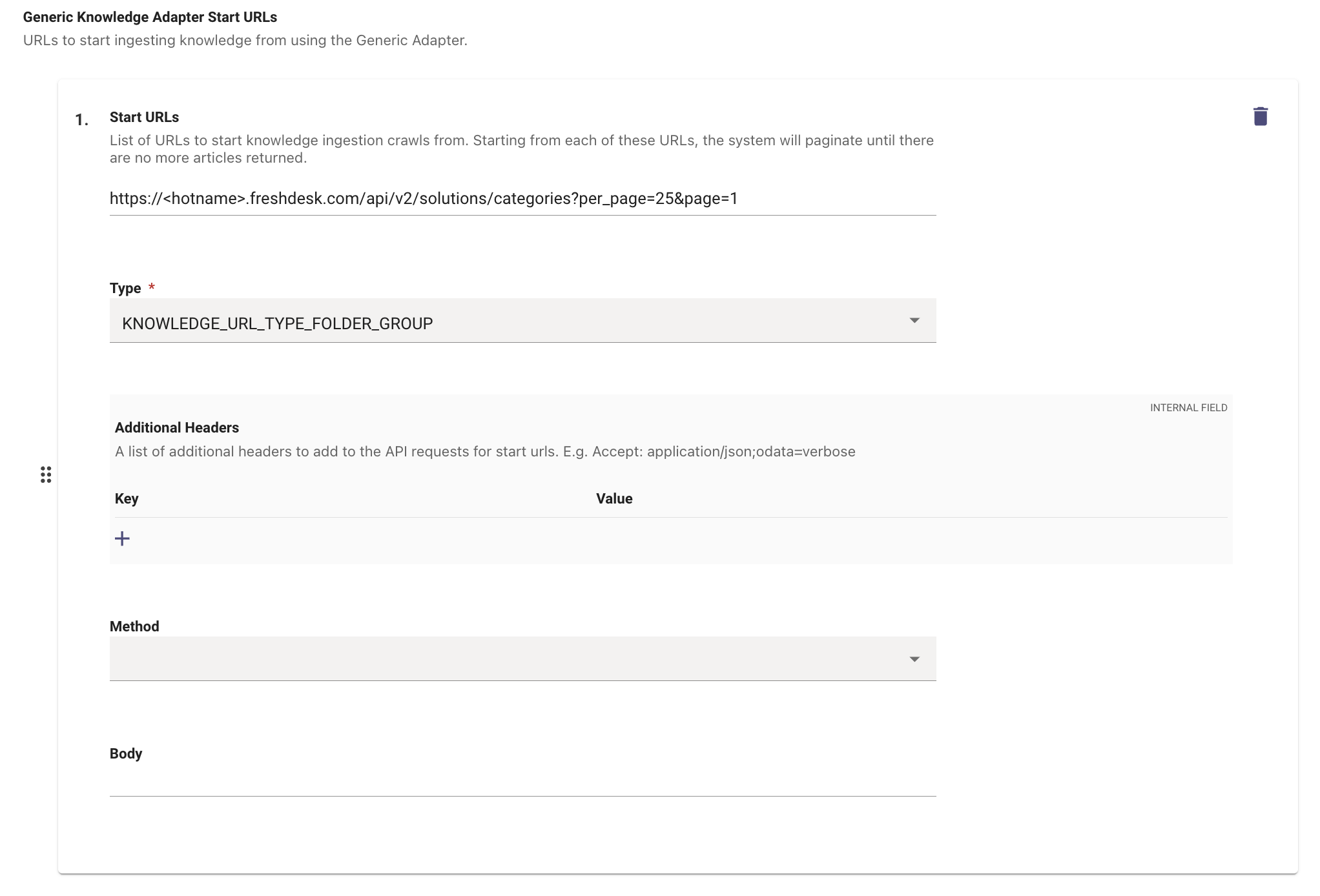
With this we are able to call a start URL, fetch the content details and map it internally.
https://<hostname>.freshdesk.com/api/v2/solutions/categories?per_page=25&page=1 -
Define the Type of content which will be received from the URL. In this case the Content type being returned is a Groups of Folder which includes the content.
Now that we have configured the Start URL and the Type of Content Moveworks can expect. We now need to map the API response to the internal Moveworks Mapping Attributes in order to successfully process the content.
Lets start by first mapping for the KNOWLEDGE_URL_TYPE_FOLDER_GROUP you would need to select this as the Type in Response Mapper
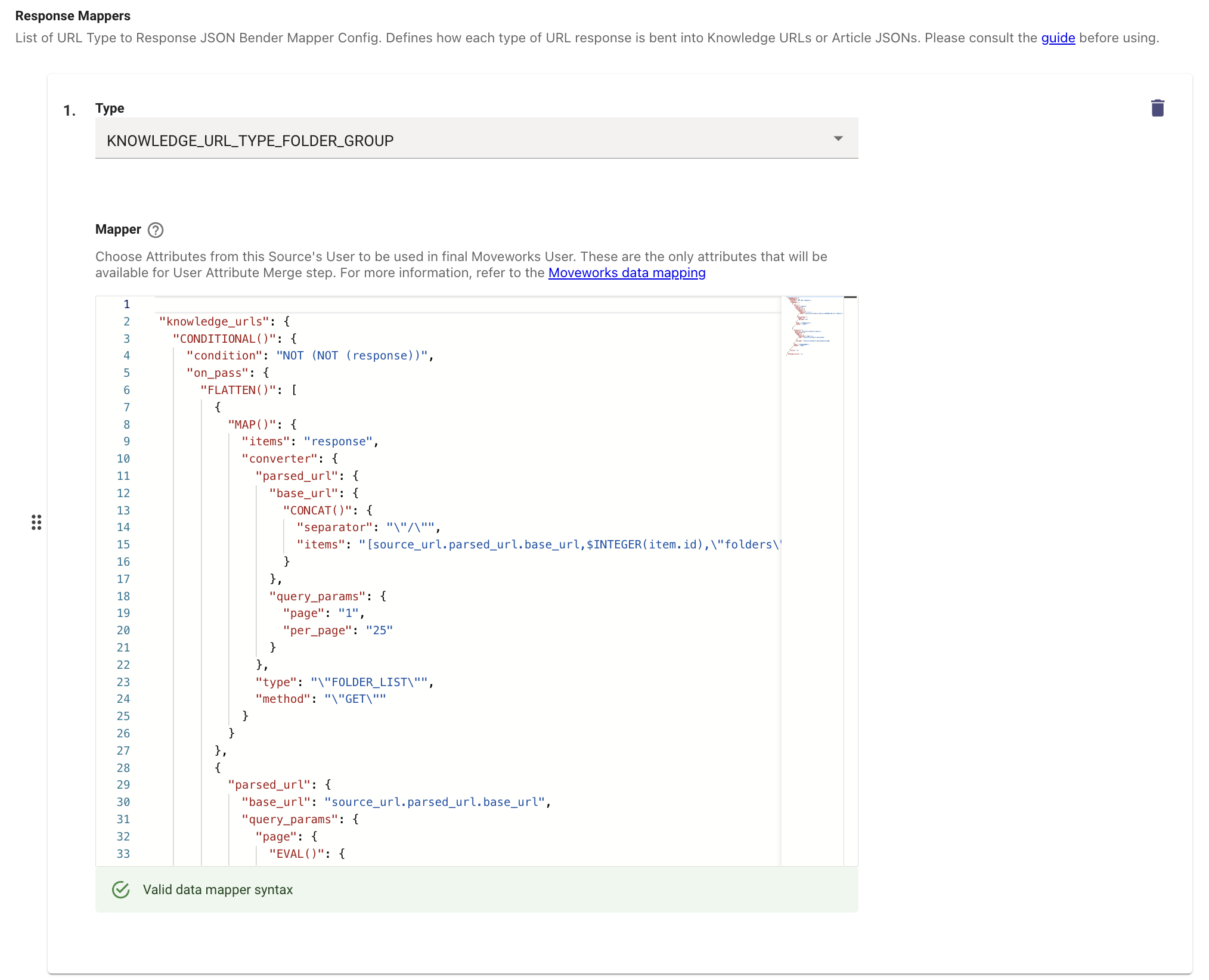
{
"knowledge_urls": {
"CONDITIONAL()": {
"condition": "NOT (NOT (response))",
"on_pass": {
"FLATTEN()": [
{
"MAP()": {
"items": "response",
"converter": {
"parsed_url": {
"base_url": {
"CONCAT()": {
"separator": "\"/\"",
"items": "[source_url.parsed_url.base_url,$INTEGER(item.id),\"folders\"]"
}
},
"query_params": {
"page": "1",
"per_page": "25"
}
},
"type": "\"FOLDER_LIST\"",
"method": "\"GET\""
}
}
},
{
"parsed_url": {
"base_url": "source_url.parsed_url.base_url",
"query_params": {
"page": {
"EVAL()": {
"expression": "page + 1",
"args": "source_url.parsed_url.query_params"
}
},
"per_page": "source_url.parsed_url.query_params.per_page"
}
},
"type": "\"FOLDER_GROUP\"",
"method": "\"GET\""
}
]
},
"on_fail": "[]"
}
},
"knowledge_articles": "[]"
}Next we will do this for KNOWLEDGE_URL_TYPE_FOLDER_LIST so we can understand where the content exists.
{
"knowledge_urls": {
"CONDITIONAL()": {
"condition": "NOT(NOT(response))",
"on_pass": {
"FLATTEN()": [
{
"MAP()": {
"items": "response",
"converter": {
"parsed_url": {
"base_url": {
"CONCAT()": {
"separator": "\"/\"",
"items": "[$REPLACE(source_url.parsed_url.base_url,\"categories.*$\", \"folders\"),$INTEGER(item.id),\"articles\"]"
}
},
"query_params": {
"page": "1",
"per_page": "25"
}
},
"type": "\"ARTICLE_LIST\"",
"method": "\"GET\""
}
}
},
{
"parsed_url": {
"base_url": "source_url.parsed_url.base_url",
"query_params": {
"page": {
"EVAL()": {
"expression": "page + 1",
"args": "source_url.parsed_url.query_params"
}
},
"per_page": "source_url.parsed_url.query_params.per_page"
}
},
"type": "\"FOLDER_LIST\"",
"method": "\"GET\""
}
]
},
"on_fail": "[]"
}
},
"knowledge_articles": "[]"
}Finally we will be mapping the Articles themselves KNOWLEDGE_URL_TYPE_ARTICLE_LIST
{
"knowledge_urls": {
"CONDITIONAL()": {
"condition": "NOT(NOT(response))",
"on_pass": [
{
"parsed_url": {
"base_url": "source_url.parsed_url.base_url",
"query_params": {
"page": {
"EVAL()": {
"expression": "page + 1",
"args": "source_url.parsed_url.query_params"
}
},
"per_page": "source_url.parsed_url.query_params.per_page"
}
},
"type": "\"ARTICLE_LIST\"",
"method": "\"GET\""
}
],
"on_fail": "[]"
}
},
"knowledge_articles": {
"CONDITIONAL()": {
"condition": "NOT(NOT(response))",
"on_pass": "response",
"on_fail": "[]"
}
}
}Once the Mapper have been configured for the 3 levels, we need to define the final Article Mapper
{
"created_at": "$TIMECONV(created_at)",
"article_id": "$TEXT($INTEGER(id))",
"article_visibility": "\"VISIBLE\"",
"article_class": "\"CONTENT_ITEM\"",
"article_hierarchies": [
{
"tier_values": "[\"\"]",
"tier_label": "\"KNOWLEDGE_BASE\""
}
],
"title": "title",
"updated_at": "$TIMECONV(updated_at)",
"article_url": {
"CONCAT()": {
"separator": "\"/\"",
"items": "[\"https://<hostname>.freshdesk.com/a/solutions/articles\", $INTEGER(id)]"
}
},
"article_state": "\"PUBLISHED\"",
"body": "description"
}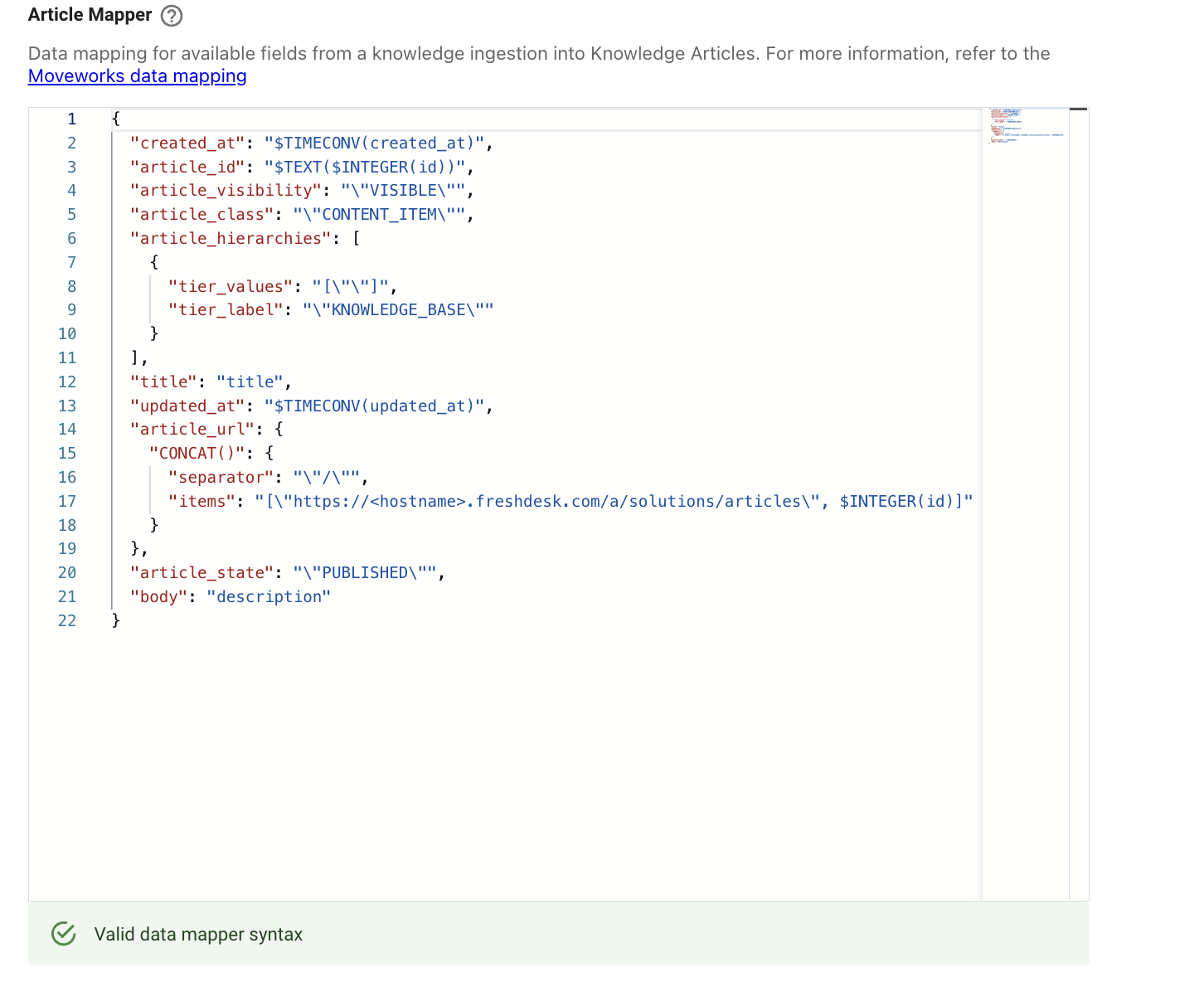
It will look something like above and you can now Save the Configuration.
Adding Permissions for the FreshDesk Content
In order to Serve Ingested knowledge in the Assistant, we need to enable permissions for the Connector which is being used to ingest the Knowledge.
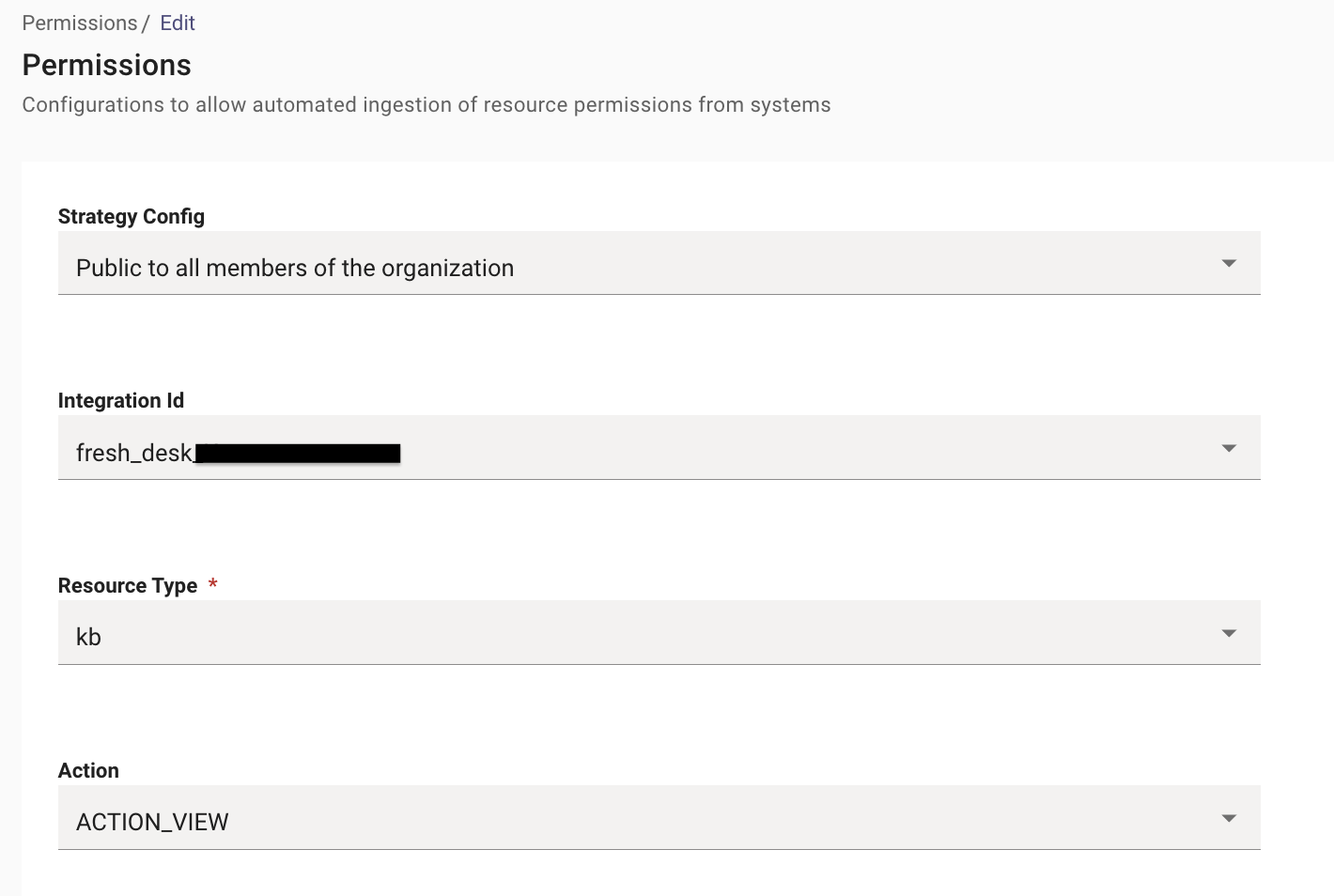
- Navigate to Resource Permissions > Permissions Rules under the Core Platform module. Click on Create.
- Here we need to define the following fields :
- Strategy Config- Public to all members of the organization
- Integration Id- Name of the connector for Fresh Desk
- Resource Type- kb
- Action- ACTION_VIEW
Validation
- Once you have submitted the Knowledge ingestion configuration, it will kick off the Ingestion pipeline in the background, the status of the same can be tracked on the Ingested Knowledge View
- You can search for the Articles with their Title's here, and if they are listing on the Console that means they have been ingested successfully.
Updated 5 months ago