Triage 2.0: Technology Overview
Overview
Here is how Triage 2.0 works:
- Triage processes tickets that pass the Triage Ticket Filter and transforms them into rich and meaningful embeddings, capturing the semantic meaning of each ticket.
- Once the embeddings are created for a ticket, Triage searches for other similar tickets, akin to comparing the ticket to a library of past tickets to find ones that are most alike.
- When a ticket is compared to others, Triage checks the labeling of the most similar past tickets to select the mode value.
- The system is designed to adapt quickly, updating itself to include changes such as new categories or assignment groups. This ensures it can handle new kinds of tickets as efficiently as the old ones.
How does this work?
This is an overview of the Triage 2.0 architecture.
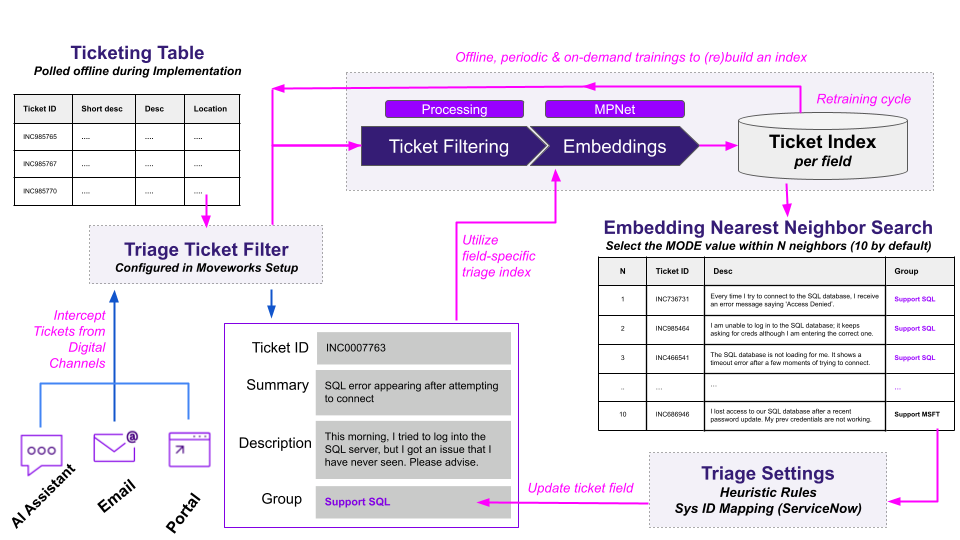
Step 1: Build an Index with Training Data
Moveworks constructs a semantic index of your tickets by mapping their descriptions into a vector embedding space. This process uses a fine-tuned version of the MPNet model to ensure that tickets with similar meaning are positioned near one another within the vector space.
The requirements for this stage are:
- Moveworks must be connected to the production instance.
- Triage ticket filters have been configured within Moveworks Setup.
- Ticketing tables have data populated.
The two-part training process:
- Data Processing: Reads all historical ticketing data from the ticketing database and filter in only tickets that pass the Triage Ticket Filter.
- Building an Index: Takes the filtered output, generates embeddings to capture the semantic meaning of each ticket, and builds an index for online predictions.
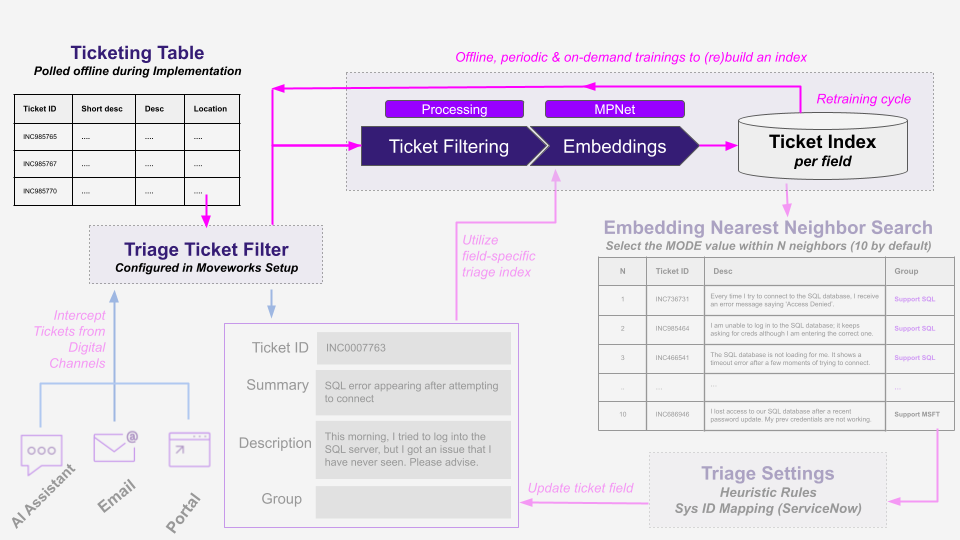
Step 2: Intercept Tickets from Digital Channels
When a new ticket is created from digital channels, such as Moveworks AI Assistant, Email, and Self-Service Portal, Moveworks will evaluate it through the Triage Ticket Filter with the following outcomes:
- If the ticket passes the Triage Ticket Filter, then it will be evaluated by Triage.
- If the ticket does not passes the Triage Ticket Filter, then it will be left alone to be handled by Moveworks Ticket Interception skill or human agents to intervene and tack action.
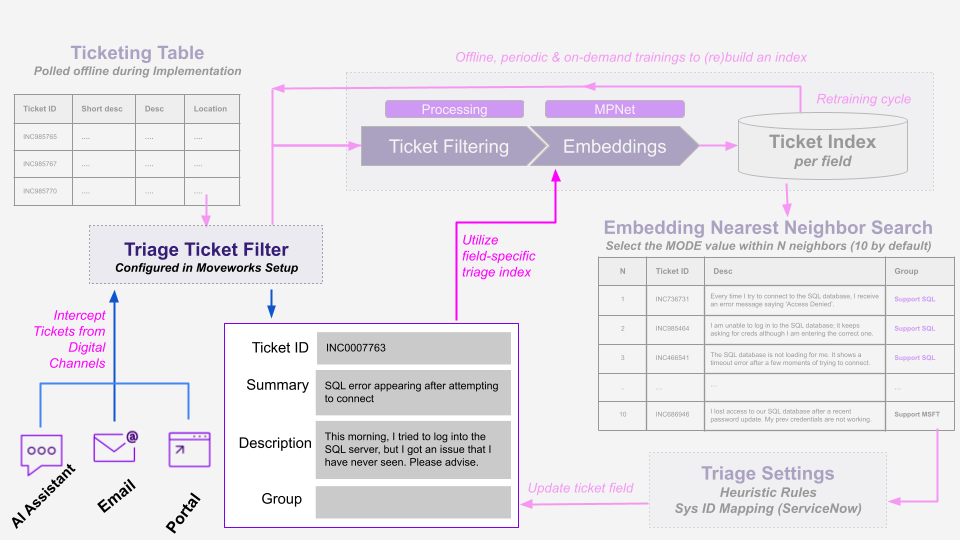
If the ticket is to be evaluated by Triage, then Moveworks will generate embeddings to get it ready for classification by the field-specific triage index, .e.g assignment group, category, subcategory, etc.
Step 3: Classify and Update Tickets
Once the embeddings are created for the ticket, Triage searches for other tickets that have similar issues or topics, comparing the ticket to a library of past tickets to find ones that are most alike. This type of search is called Embedding Nearest Neighbor (ENN) with the following steps:
- retrieves the top N most relevant tickets, in which N = 10 by default
- computes the mode value of the field for classification
- selects the value for classification
- modified the value based on any Triage settings
- Heuristic Rules can override the prediction based on keyword-match, for example
- Sys ID Mapping can convert any predicted value from sys_id (not shown in diagram but would another column on the table) to display name, based on the daily ingestion from ServiceNow. If a sys_id is found to be
inactivethen Triage will drop the prediction.
- updates the ticket field
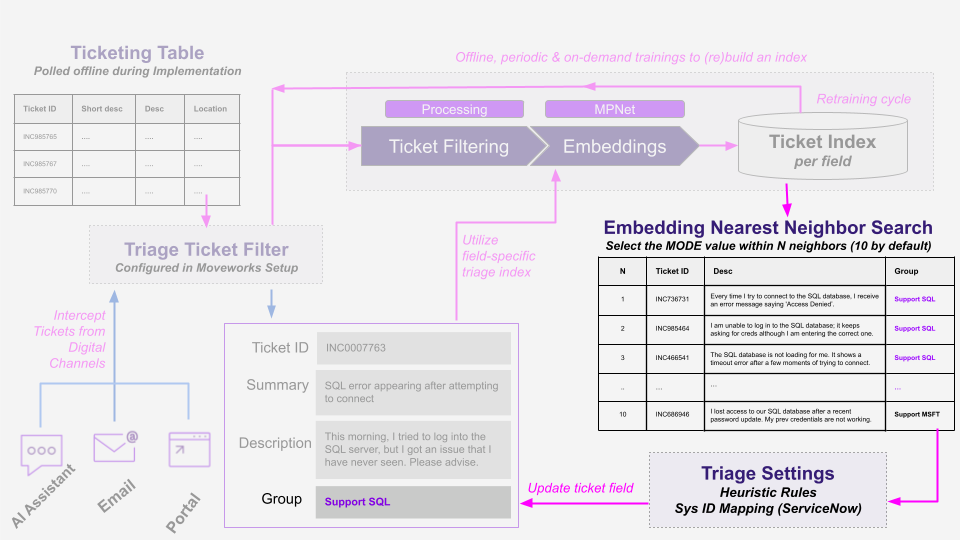
For example, an incoming ticket (INC0007763) is searched within the index to find that the top 10 most relevant tickets had Support-SQL as the majority value for “group.”
How does the index refresh?
In any enterprise setting, the labels of ticket fields, e.g. assignment group, service offering, etc, are created and deprecated regularly within a Service Desk. Therefore, Triage will need to be able to update its index with the latest data. Moveworks offers two approaches:
- Automatically: Index will be updated on a monthly basis with a rolling window of 12 months, selecting 5000 ticket samples.
- [Later in Limited Preview] On Demand: For sudden introduction of new labels like an important assignment group, Moveworks will offer the ability for on-demand index refresh.
What are the advantages of this new architecture?
- Relaxed data requirements: Less data and no data distribution requirements required for Triage, due to the embeddings + index infrastructure.
- Transparent explainability: We can inspect all the nearest neighbors to see clearly why a prediction was made on a specific ticket for troubleshooting purposes.
- Improved overall performance: Based on offline analysis of existing set of customers, Triage 2.0 performs as good or better than the current product architecture, irrespective of the digital channel, e.g. chat, email, portal.
Are there any technical limitations?
Triage 2.0 is in Limited Preview and will make routine improvements. As of Nov 18, 2025, here are the limits:
- Limited Availability on select Data Centers: Triage 2.0 is available on all MW Data centers - US, EU, CA, AU, and GovCloud.
- Optimized for multilingual tickets: Supports multilingual, including english, tickets via 500M snowflake arctic v2 embeddings model.
Updated 2 months ago