Workday
Overview
With the Workday content connector, Moveworks Enterprise Search enables the Moveworks AI Assistant to answer user’s questions directly in chat, by understanding the questions and responding instantly with answers containing the most relevant content, links to knowledge base articles or files, or links to external articles taken from trusted knowledge sources.
Architecture
The following diagram shows the high level architecture of how Moveworks integrates with Workday’s knowledge base.
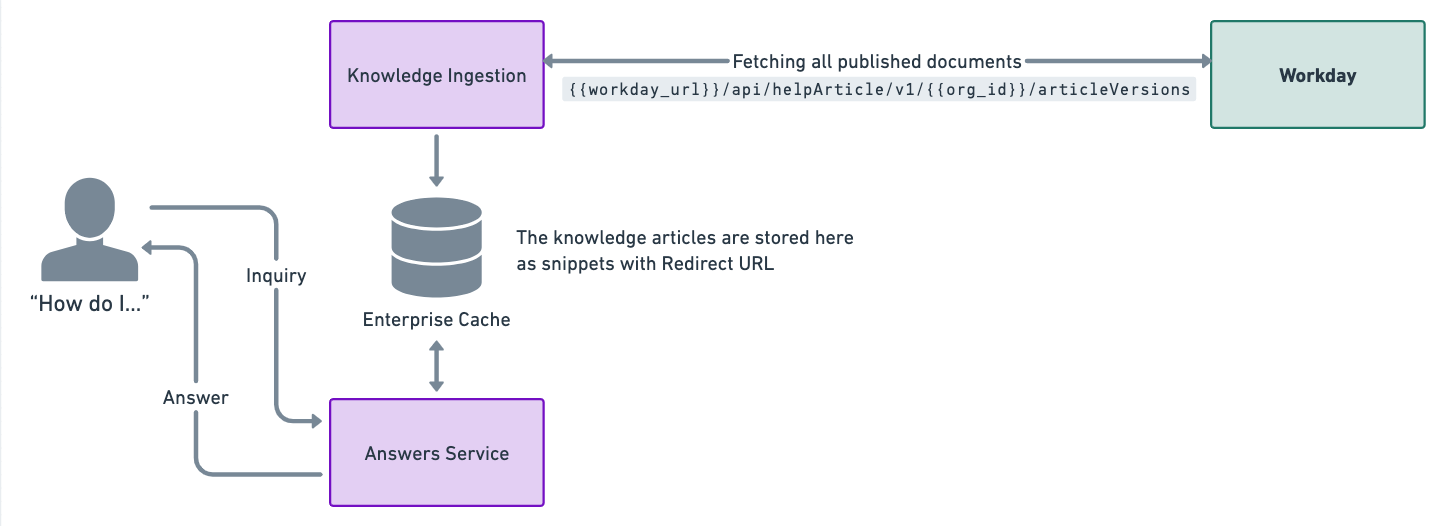
This is a live integration where we poll knowledge articles every four hours. This is done so that the enterprise cache is updated with relevant snippets for answers.
Our enterprise cache stores the knowledge articles from Workday and generates relevant knowledge snippets by understanding the content. We also store the redirect urls in order serve them to users to direct them to where the document is stored and can be read.
Authentication
The authentication in Workday platforms is performed by passing a Bearer Token created by sending a POST request to an OAuth API using the Client ID, Secret and a Refresh Token.
See Workday - Access Requirements (Knowledge) for more details.
Ingestion
Workday’s helpArticle API is used to fetch and ingest the knowledge articles.
How do we fetch knowledge articles from Workday
We use the following APIs to fetch the knowledge articles that you want Moveworks to ingest.
Fetch all knowledge articles
GET
curl --location 'https://wd2-impl-services1.workday.com/ccx/api/helpArticle/v1/{{organization-id}}/articleVersions?status={{status_id}}&limit={{limit}}&offset={{offset}}' \
--header 'Authorization: Bearer <generated_token>'Integration Scope
Content
Our knowledge ingestion engine works on ingesting the content section from the API response which is a text block with paragraphs separated by a \n separator.
Currently we ingest all articles with status = Published (all published articles). We also have an option to add an extra layer of filter with audience = Public to fetch only content that is available to everyone. Please confirm with your Moveworks Implementation team if this is suitable for you.
Snippet Titles
Note that outside of just using your title, we will also parse the rest of the article content to determine the best title for your article.
Article Response:
{
"title": "VPN Troubleshooting Guide",
"content": "{{SEE RIGHT}}"
}Content Text Body:
How to solve connection errors.\nHere are some instructions.
How to solve VPN slowness\n
Here are some other instructions.\nIn this example, we will create a knowledge article “snippet” titled “VPN Troubleshooting Guide: How to solve connection errors”.
End user experience
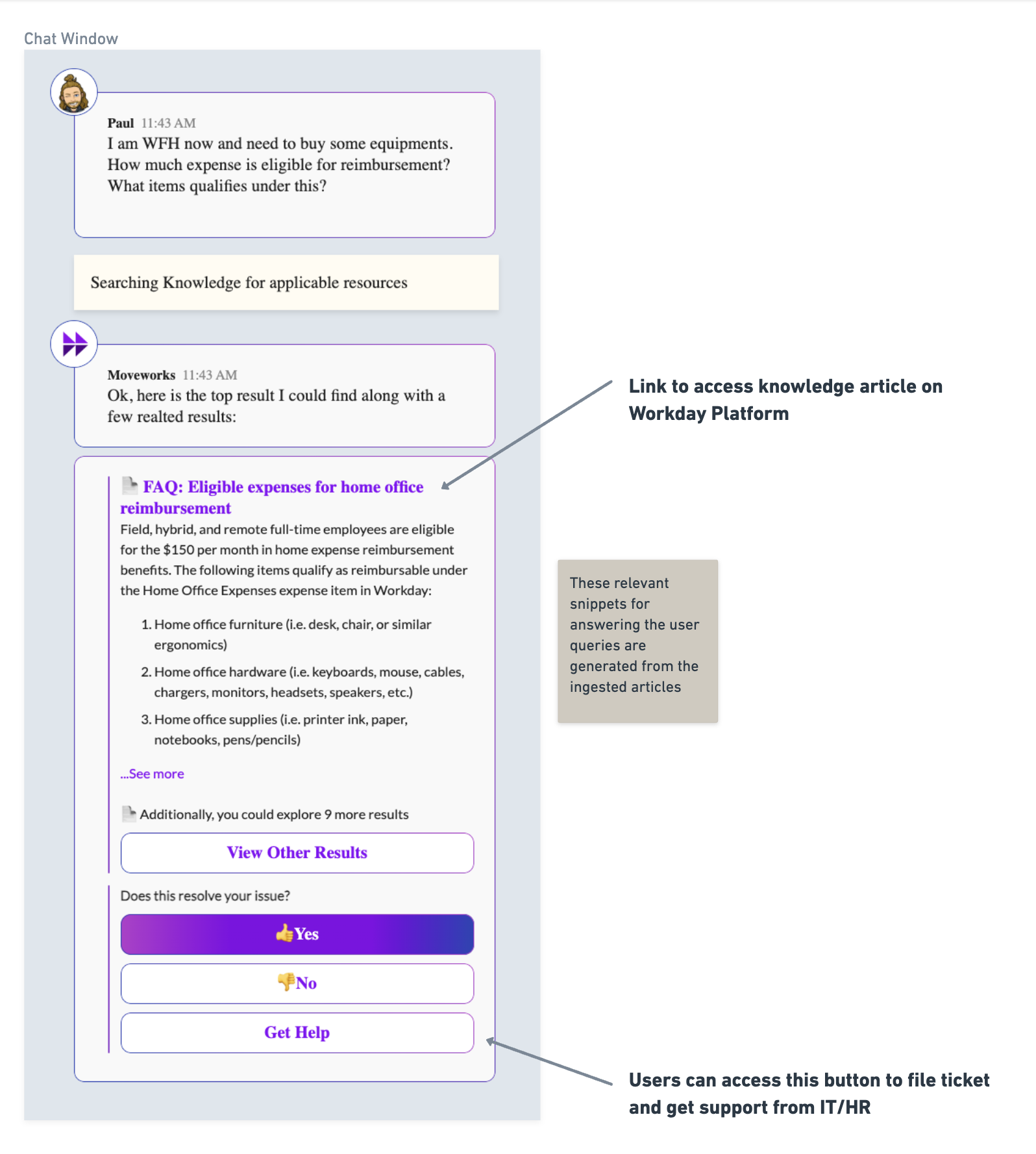
Case 1: When bot gets relevant documents for the user inquiry (Success Case)
If there is any document which can solve the user’s query, the bot will present the answer in the following format with a redirect heading and a relevant knowledge snippet.
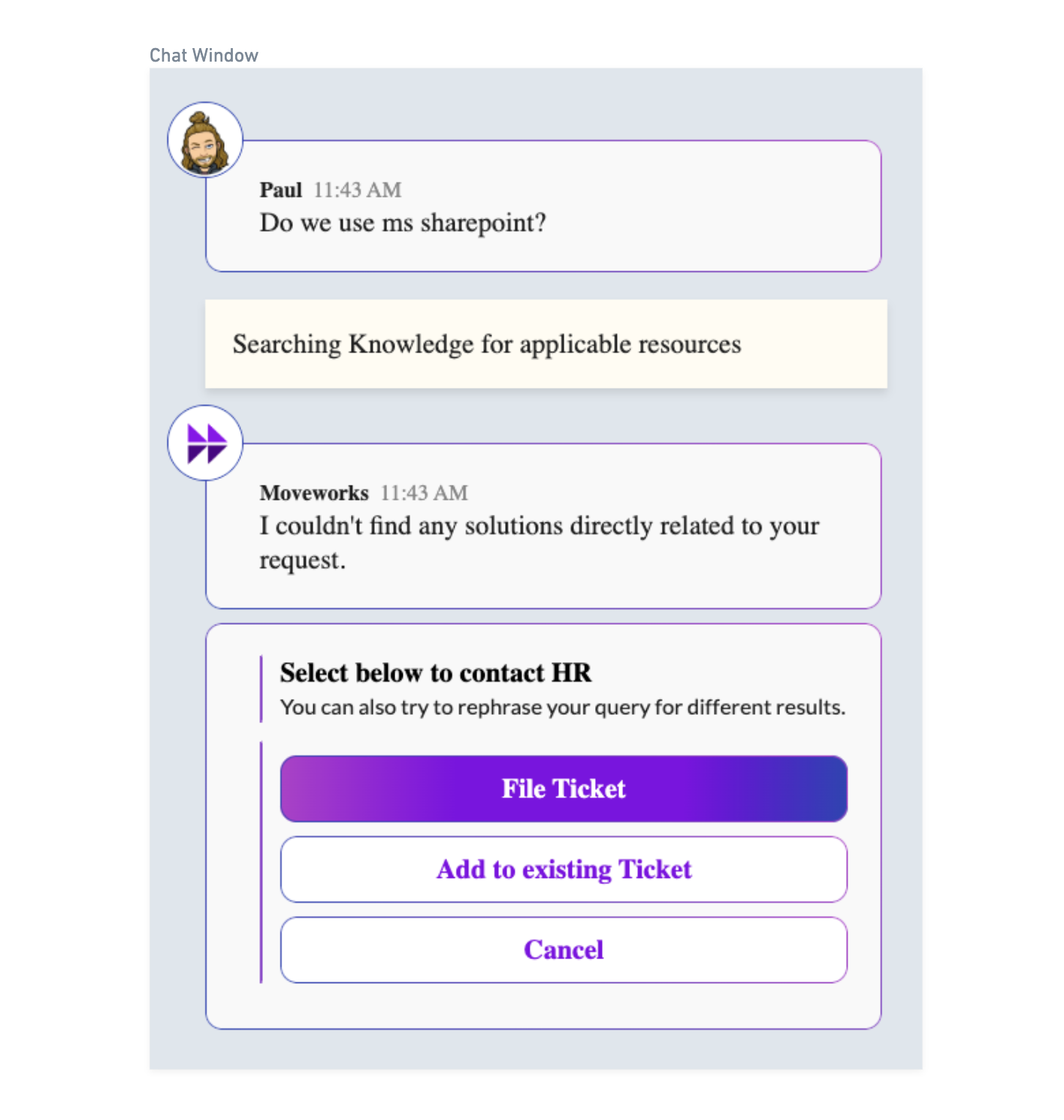
Case 2: When bot doesn’t have any relevant answers to user inquiry (Backstop Case)
This would be the answer provided to the user if the bot doesn’t find any relevant answers from the available documents.
Updated 8 months ago