How to build raw interactions table using Data API
This document describes the process of reconstructing the Raw Interactions table using data retrieved from the Data API.
The Data API provides raw data in a normalized format, split across multiple related tables. To recreate the unified Raw Interactions view, these tables must be joined and transformed to align with the structure and semantics of the original dataset.
In this exercise, we download the raw data into an Excel file and perform the necessary transformations within Excel to build the final view.
Step - 1 : Fetching and storing data into CSV files.
The Data API distributes raw data across five key tables: Conversations, Interactions, Plugin Calls, Plugin Resources, and Users.
We use a Python script to fetch data from the past 24 hours and generate an Excel file containing all five tables.
You can copy the script into your environment and execute it. Be sure to replace the placeholder for the API key with your actual Data API credentials before running the script.
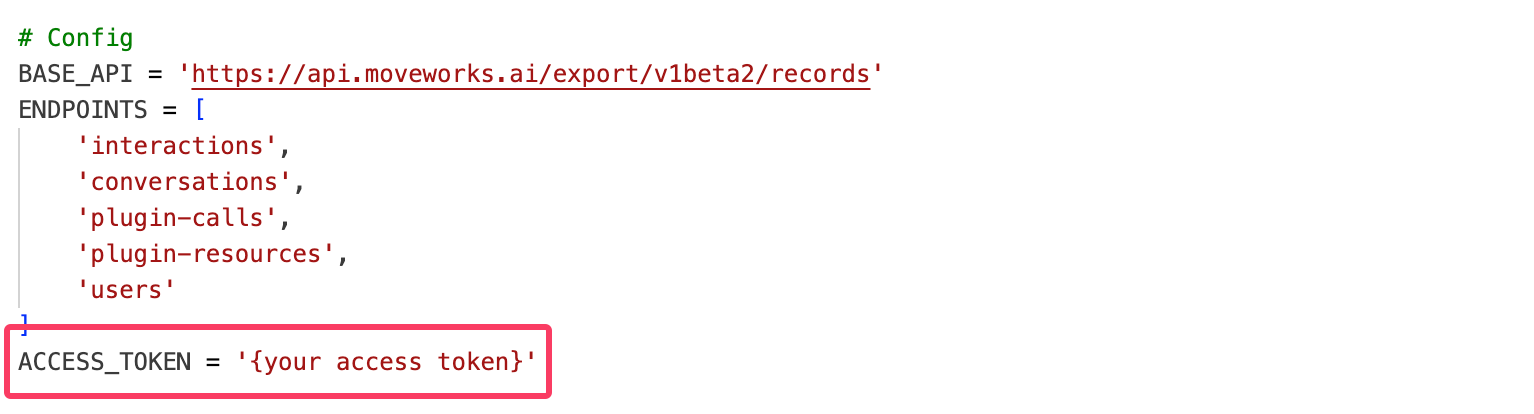
Python script
import requests
import pandas as pd
import time
import logging
from pathlib import Path
import re
# Config
BASE_API = 'https://api.moveworks.ai/export/v1beta2/records'
ENDPOINTS = [
'interactions',
'conversations',
'plugin-calls',
'plugin-resources',
'users'
]
ACCESS_TOKEN = '<Access Token>' # Replace this
# Filter time window (applied to all endpoints)
TIME_FILTER = "last_updated_time ge '2025-07-15T00:00:00.000Z' and last_updated_time le '2025-07-16T00:00:00.000Z'"
# Setup logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# Headers
headers = {
'Authorization': f'Bearer {ACCESS_TOKEN}',
}
# Retry config
MAX_RETRIES = 5
# Function to clean illegal characters
def clean_illegal_chars(df):
def remove_illegal_chars(value):
if isinstance(value, str):
return re.sub(r'[�-
- ]', '', value)
return value
return df.applymap(remove_illegal_chars)
# Flatten nested fields
def flatten_record(record):
flat = record.copy()
if isinstance(flat.get("detail"), dict):
detail = flat.pop("detail", {}) or {}
for key, value in detail.items():
if isinstance(value, list):
value = ','.join(map(str, value))
flat[f'detail_{key}'] = value
return flat
# Collect data per endpoint
all_dataframes = {}
def fetch_data(endpoint):
url = f'{BASE_API}/{endpoint}'
params = {
'$orderby': 'id desc',
'$filter': TIME_FILTER,
}
data = []
retries = 0
page_count = 0
logging.info(f"Fetching data from /{endpoint}")
while url:
try:
logging.info(f"Requesting page {page_count + 1}: {url}")
response = requests.get(url, headers=headers, params=params if url.endswith(endpoint) else None)
if response.status_code == 200:
json_resp = response.json()
page_data = json_resp.get('value', [])
logging.info(f"Retrieved {len(page_data)} records from page {page_count + 1}")
if not page_data:
break
for record in page_data:
data.append(flatten_record(record))
url = json_resp.get('@odata.nextLink')
retries = 0
page_count += 1
if endpoint == 'users':
time.sleep(2)
elif response.status_code == 429:
wait = 90 if endpoint == 'users' else 60
logging.warning(f"Rate limited on /{endpoint}. Waiting for {wait} seconds.")
time.sleep(wait)
elif response.status_code in (500, 502, 503, 504):
if retries < MAX_RETRIES:
wait = 2 ** retries
logging.warning(f"Transient error {response.status_code} on /{endpoint}. Retrying in {wait} seconds...")
time.sleep(wait)
retries += 1
else:
logging.error(f"Max retries reached on /{endpoint}. Aborting.")
break
else:
logging.error(f"Unexpected error {response.status_code} on /{endpoint}: {response.text}")
break
except Exception as e:
logging.exception(f"Exception occurred while calling /{endpoint}")
break
if data:
df = pd.DataFrame(data)
df = clean_illegal_chars(df)
all_dataframes[endpoint] = df
logging.info(f"Ingestion complete for /{endpoint}, {len(df)} records.")
else:
logging.info(f"No data retrieved from /{endpoint}.")
# Run ingestion for all endpoints
for endpoint in ENDPOINTS:
fetch_data(endpoint)
# Save to Excel with one sheet per endpoint
if all_dataframes:
output_file = Path("moveworks_export.xlsx")
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
for endpoint, df in all_dataframes.items():
sheet_name = endpoint[:31] # Excel sheet name max limit
df.to_excel(writer, sheet_name=sheet_name, index=False)
logging.info(f"All data written to {output_file}")
else:
logging.warning("No data to write to Excel.")
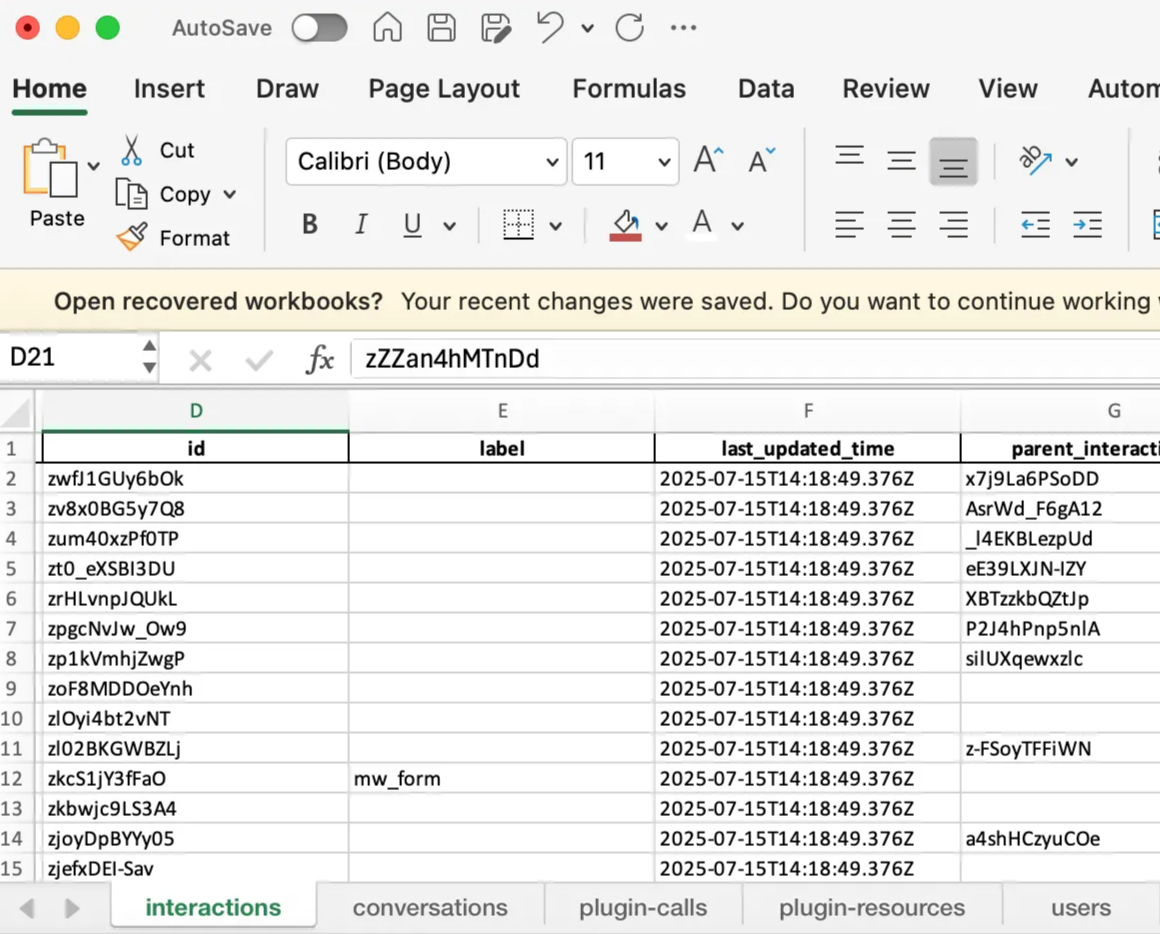
Step - 2 : Modification of the excel file to generate the raw interactions view.
Let’s learn the sequence of columns shown in raw interactions table and understand where this data is stored in Data API
Raw interactions table | Definition | Data API table |
|---|---|---|
Timestamp | This the created time for user interaction | Interactions |
Conversation ID | Conversation ID attributed to an interaction stored | Interactions |
Conversation Domain | This is detected domain on a conversation level | Conversations |
Conversation Topic | All topics aggregated for interactions based on the conversation ID | Interactions |
Interaction Type | Type of interaction | Interactions |
Interaction content | User message or action information | Interactions |
Bot Response | Summarized response provided by the AI Assistant | Interactions |
Unsuccessful Plugins | Plugins called by the AI Assistant but were not served and not used | Plugin calls |
Plugin Served | Plugins that the reasoner considered and served to the user | Plugin calls |
Plugin Used | Plugins that the user interacted or engaged with | Plugin calls |
Resource Domain | Resource domain configured during setting up the ingestion. | Plugin resource |
No of citations | Total no of citations provided in the summarized response | Plugin resource |
Content Item name | Name of the content item used to generate the summarized response | Plugin resource |
Content Item ID | External resource ID of the content item | Plugin resource |
Ticket type | Indicates who filed the ticket
| Plugin resource |
Ticket ID | Unique identifier for a ticket | Plugin resource |
Interaction surface | Platform where the interaction took place | Interactions |
User Department | Department to which the end user belongs to | |
User Location | Location to which the end user belongs to | |
User country | Country to which the end user belongs to | |
User Preferred language | Default language configured in the AI Assistant | Users |
Now that we have identified the columns required to reconstruct the Raw Interactions view, let’s begin working through the raw data and progressively merge the interactions and conversations tables to form a unified view. Please note that we will be using Excel functions throughout this process.
-
Bring in the base columns — Actor, Conversation ID, Created Time, Interaction ID, Interaction Type
a. From the interactions sheet, extract the relevant details into a new sheet. We are only interested in user-led interactions.
Use the following formula to filter this data:
=FILTER(interactions!A:D, interactions!A:A="user") -
Using the Conversation ID, fetch Conversation Domain and Conversation Topic
a. To fetch the Conversation Domain, use the
VLOOKUPfunction to pull data from the conversations sheet:=VLOOKUP(B4,conversations!B:E,3,FALSE)b. To recreate the Conversation Topic, aggregate all topics detected at the interaction level and replicate them for each interaction.
Use this formula:
=TEXTJOIN(", ", TRUE, UNIQUE(FILTER(interactions!P:P, interactions!B:B= B2))) -
Fetch additional content fields from the Interactions table
a. To extract Interaction Content, pull values from
detail_content,detail_detail, or similar columns, and combine them based on data availability. Use the following nestedIFstructure:=IF(INDEX(interactions!K:K, MATCH(D1294, interactions!D:D, 0))<>"", INDEX(interactions!K:K, MATCH(D1294, interactions!D:D, 0)), IF(INDEX(interactions!N:N, MATCH(D1294, interactions!D:D, 0))<>"", INDEX(interactions!N:N, MATCH(D1294, interactions!D:D, 0)), IF(INDEX(interactions!L:L, MATCH(D1294, interactions!D:D, 0))<>"", INDEX(interactions!L:L, MATCH(D1294, interactions!D:D, 0)), IF(INDEX(interactions!Q:Q, MATCH(D1294, interactions!D:D, 0))<>"", INDEX(interactions!Q:Q, MATCH(D1294, interactions!D:D, 0)), ""))))b. To retrieve the Bot Response corresponding to each user interaction, use the parent interaction ID to index into bot-led interactions:
=TEXTJOIN(CHAR(10), TRUE, FILTER(interactions!K:K, interactions!G:G=D2))There can be multiple bot interactions pointing to a single user interaction. Join these interactions to form a bot response similar to raw interactions table.
-
Determine plugins involved in an interaction using the Plugin Calls table
Retrieve three plugin-related columns using the formulas below:
a. Unsuccessful plugin:
=TEXTJOIN(", ", TRUE,FILTER('plugin-calls'!F:F,('plugin-calls'!D:D=D10) *('plugin-calls'!H:H =FALSE) *('plugin-calls'!I:I=FALSE)))b. Plugin served:
=TEXTJOIN(", ", TRUE,FILTER('plugin-calls'!F:F,('plugin-calls'!D:D=D10) *('plugin-calls'!H:H =TRUE)))c. Plugin used:
=TEXTJOIN(", ", TRUE,FILTER('plugin-calls'!F:F,('plugin-calls'!D:D=D10) *('plugin-calls'!H:H =TRUE) *('plugin-calls'!I:I=TRUE))) -
Add plugin resource information
Use the plugin-resources table to fetch citation and content-related metadata:
a. Resource Domain: Indicates the configured domain for knowledge or ticket-based interactions.
=TEXTJOIN(", ", TRUE, UNIQUE(FILTER('plugin-resources'!K:K, 'plugin-resources'!E:E = D2)))b. Number of Citations: Counts distinct resources cited per interaction.
=IFERROR(COUNTA(UNIQUE(FILTER('plugin-resources'!D:D, 'plugin-resources'!E:E = D2))), 0)Note: Even when there's a #CALC! error, Excel may return 1. Use the Content Item ID column to clean up any incorrect entries.
c. Content Item ID:
=TEXTJOIN(", ", TRUE, UNIQUE(FILTER('plugin-resources'!D:D, 'plugin-resources'!E:E = D2)))Filter out rows returning
#CALC!. For such rows, mark No of Citations as 1 and Content Item ID as "Nil".d. Content Item Name:
=TEXTJOIN(", ", TRUE, UNIQUE(FILTER('plugin-resources'!M:M, 'plugin-resources'!E:E = D2))) -
Populate ticketing information (only applicable when a ticket is created)
a. Ticket Type: Indicates whether a ticket was user-initiated or bot-initiated.
=TEXTJOIN(", ", TRUE, UNIQUE(FILTER('plugin-resources'!S:S, 'plugin-resources'!E:E = D2)))b. Ticket ID: Filter the values to include only rows where the resource type is "ticket".
=TEXTJOIN(", ", TRUE, UNIQUE(FILTER('plugin-resources'!H:H,('plugin-resources'!E:E = D4)*('plugin-resources'!I:I="RESOURCE_TYPE_TICKET")))) -
Fetch the platform where the interaction took place
This can be extracted from the interactions sheet based on Interaction ID:
=TEXTJOIN(", ", TRUE, UNIQUE(FILTER(interactions!H:H, interactions!D:D = D2))) -
Get the user’s preferred language from the Users table
Use this formula to fetch preferred language based on user ID:
=TEXTJOIN(", ",TRUE,UNIQUE(FILTER(users!J:J,users!F:F=F3)))
Additional Notes:
Fields like User Department, User Location, and User Country are not directly available from the Data API. These attributes must be sourced from your organization’s external identity systems.
The User API provides an external ID which can be used to enrich user metadata by integrating with external identity providers such as Okta. You can refer to Okta List Users for details. Once this data is pulled from the external system, join it using the external ID to populate the missing attributes.
While the modifications shown here are demonstrated in Excel, we are also providing a Python script that can directly generate a raw interactions table based on the time input specified in the script
To run a Python file, first install Python from python.org. On Mac, open Terminal, navigate to your file’s folder, and run python3 script.py. On Windows, open Command Prompt, go to the file’s folder, and run python script.py.
import requests
import pandas as pd
import time
import logging
from pathlib import Path
import re
from datetime import datetime, timedelta
# Config
BASE_API = 'https://api.moveworks.ai/export/v1beta2/records'
ENDPOINTS = [
'interactions',
'conversations',
'plugin-calls',
'plugin-resources',
'users'
]
ACCESS_TOKEN = '<Access Token>' # Replace this
# Time filter will be set dynamically based on user input
# Setup logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# Headers
headers = {
'Authorization': f'Bearer {ACCESS_TOKEN}',
}
# Retry config
MAX_RETRIES = 5
def get_user_date_inputs():
"""Get start and end dates from user input and convert to timestamp format"""
print("\n" + "="*50)
print("RAW INTERACTIONS TABLE BUILDER")
print("="*50)
print("Enter the date range for data extraction:")
print("Date format: YYYY-MM-DD (e.g., 2025-07-15)")
print("-"*50)
while True:
try:
start_date_str = input("Enter start date (YYYY-MM-DD): ").strip()
start_date = datetime.strptime(start_date_str, "%Y-%m-%d")
break
except ValueError:
print("❌ Invalid date format. Please use YYYY-MM-DD format (e.g., 2025-07-15)")
while True:
try:
end_date_str = input("Enter end date (YYYY-MM-DD): ").strip()
end_date = datetime.strptime(end_date_str, "%Y-%m-%d")
if end_date < start_date:
print("❌ End date cannot be earlier than start date. Please try again.")
continue
break
except ValueError:
print("❌ Invalid date format. Please use YYYY-MM-DD format (e.g., 2025-07-15)")
# Convert to timestamp format for API
start_timestamp = start_date.strftime("%Y-%m-%dT00:00:00.000Z")
# For end date, set to end of day
end_timestamp = (end_date + timedelta(days=1) - timedelta(microseconds=1)).strftime("%Y-%m-%dT23:59:59.999Z")
time_filter = f"last_updated_time ge '{start_timestamp}' and last_updated_time le '{end_timestamp}'"
print(f"\n✅ Date range set:")
print(f" Start: {start_date_str} 00:00:00 UTC")
print(f" End: {end_date_str} 23:59:59 UTC")
print(f" Filter: {time_filter}")
print("-"*50)
return time_filter, start_date_str, end_date_str
def clean_illegal_chars(df):
"""Clean illegal characters from DataFrame"""
def remove_illegal_chars(value):
if isinstance(value, str):
return re.sub(r'[\x00-\x08\x0B\x0C\x0E-\x1F]', '', value)
return value
return df.applymap(remove_illegal_chars)
def flatten_record(record):
"""Flatten nested fields in record"""
flat = record.copy()
if isinstance(flat.get("detail"), dict):
detail = flat.pop("detail", {}) or {}
for key, value in detail.items():
if isinstance(value, list):
value = ','.join(map(str, value))
flat[f'detail_{key}'] = value
return flat
def fetch_data(endpoint, time_filter): # Added time_filter parameter
"""Fetch data from a specific endpoint"""
url = f'{BASE_API}/{endpoint}'
params = {
'$orderby': 'id desc',
'$filter': time_filter, # Using the passed time_filter
}
data = []
retries = 0
page_count = 0
logging.info(f"Fetching data from /{endpoint}")
while url:
try:
logging.info(f"Requesting page {page_count + 1}: {url}")
response = requests.get(url, headers=headers, params=params if url.endswith(endpoint) else None)
if response.status_code == 200:
json_resp = response.json()
page_data = json_resp.get('value', [])
logging.info(f"Retrieved {len(page_data)} records from page {page_count + 1}")
if not page_data:
break
for record in page_data:
data.append(flatten_record(record))
url = json_resp.get('@odata.nextLink')
retries = 0
page_count += 1
if endpoint == 'users':
time.sleep(2)
elif response.status_code == 429:
wait = 90 if endpoint == 'users' else 60
logging.warning(f"Rate limited on /{endpoint}. Waiting for {wait} seconds.")
time.sleep(wait)
elif response.status_code in (500, 502, 503, 504):
if retries < MAX_RETRIES:
wait = 2 ** retries
logging.warning(f"Transient error {response.status_code} on /{endpoint}. Retrying in {wait} seconds...")
time.sleep(wait)
retries += 1
else:
logging.error(f"Max retries reached on /{endpoint}. Aborting.")
break
else:
logging.error(f"Unexpected error {response.status_code} on /{endpoint}: {response.text}")
break
except Exception as e:
logging.exception(f"Exception occurred while calling /{endpoint}")
break
if data:
df = pd.DataFrame(data)
df = clean_illegal_chars(df)
logging.info(f"Ingestion complete for /{endpoint}, {len(df)} records.")
return df
else:
logging.info(f"No data retrieved from /{endpoint}.")
return pd.DataFrame()
def get_conversation_topics(interactions_df, conversation_id):
"""Get all entities for a conversation ID"""
entities = interactions_df[interactions_df['conversation_id'] == conversation_id]['detail_entity'].dropna().unique()
return ', '.join([str(e) for e in entities if str(e) != 'nan'])
def get_interaction_content(row, interactions_df):
"""Extract interaction content from detail fields"""
interaction_id = row['id']
interaction_row = interactions_df[interactions_df['id'] == interaction_id]
if interaction_row.empty:
return ""
interaction_row = interaction_row.iloc[0]
# Based on API example, only use fields that actually exist
# From the example: detail.content is the main field for user message content
if 'detail_content' in interaction_row and pd.notna(interaction_row['detail_content']) and str(interaction_row['detail_content']) != '':
return str(interaction_row['detail_content'])
return ""
def get_bot_response(row, interactions_df):
"""Get bot response using parent interaction ID"""
interaction_id = row['id']
# Find bot interactions with this interaction as parent
bot_response = interactions_df[
(interactions_df['parent_interaction_id'] == interaction_id) &
(interactions_df['actor'] == 'bot')
]
if not bot_response.empty:
bot_row = bot_response.iloc[0]
# Only use the content field that actually exists in the API
if 'detail_content' in bot_row and pd.notna(bot_row['detail_content']) and str(bot_row['detail_content']) != '':
return str(bot_row['detail_content'])
return ""
def get_plugin_info(interaction_id, plugin_calls_df, plugin_type):
"""Get plugin information based on type (unsuccessful, served, used)"""
if plugin_calls_df.empty:
return ""
interaction_plugins = plugin_calls_df[plugin_calls_df['interaction_id'] == interaction_id]
if interaction_plugins.empty:
return ""
if plugin_type == 'unsuccessful':
# Plugins that were not served and not used
plugins = interaction_plugins[
(interaction_plugins['served'] == False) &
(interaction_plugins['used'] == False)
]['plugin_name'].unique()
elif plugin_type == 'served':
# Plugins that were served
plugins = interaction_plugins[
interaction_plugins['served'] == True
]['plugin_name'].unique()
elif plugin_type == 'used':
# Plugins that were served and used
plugins = interaction_plugins[
(interaction_plugins['served'] == True) &
(interaction_plugins['used'] == True)
]['plugin_name'].unique()
else:
return ""
return ', '.join([str(p) for p in plugins if str(p) != 'nan'])
def get_resource_info(interaction_id, plugin_resources_df, info_type):
"""Get resource information (domain, citations, content items, tickets)"""
if plugin_resources_df.empty:
return "" if info_type != 'citation_count' else 0
interaction_resources = plugin_resources_df[plugin_resources_df['interaction_id'] == interaction_id]
if interaction_resources.empty:
return "" if info_type != 'citation_count' else 0
if info_type == 'domain':
domains = interaction_resources['detail_domain'].dropna().unique()
return ', '.join([str(d) for d in domains if str(d) != 'nan'])
elif info_type == 'citation_count':
unique_resources = interaction_resources['resource_id'].dropna().nunique()
return unique_resources
elif info_type == 'content_item_id':
# Use external_resource_id from detail field
content_ids = interaction_resources['detail_external_resource_id'].dropna().unique()
return ', '.join([str(c) for c in content_ids if str(c) != 'nan'])
elif info_type == 'content_item_name':
content_names = interaction_resources['detail_name'].dropna().unique()
return ', '.join([str(c) for c in content_names if str(c) != 'nan'])
elif info_type == 'ticket_type':
# Need to determine ticket type logic based on your business rules
# This might need adjustment based on how you determine user vs bot initiated
ticket_resources = interaction_resources[ticket_resources['type'] == 'RESOURCE_TYPE_TICKET']
if not ticket_resources.empty:
return "user initiated ticket" # Default, adjust logic as needed
return ""
elif info_type == 'ticket_id':
ticket_resources = interaction_resources[interaction_resources['type'] == 'RESOURCE_TYPE_TICKET']
ticket_ids = ticket_resources['detail_external_resource_id'].dropna().unique()
return ', '.join([str(t) for t in ticket_ids if str(t) != 'nan'])
return ""
def get_interaction_surface(interaction_id, interactions_df):
"""Get the platform/surface where interaction took place"""
interaction_row = interactions_df[interactions_df['id'] == interaction_id]
if not interaction_row.empty:
# Use 'platform' field from the API response
surface = interaction_row.iloc[0].get('platform', '')
return str(surface) if pd.notna(surface) else ""
return ""
def get_user_language(user_id, users_df):
"""Get user's preferred language"""
if users_df.empty:
return ""
# Use the actual field name from API response
user_row = users_df[users_df['id'] == user_id]
if not user_row.empty:
language = user_row.iloc[0].get('user_preferred_language', '')
return str(language) if pd.notna(language) else ""
return ""
def build_raw_interactions_table(all_dataframes):
"""Build the final raw interactions table"""
logging.info("Building raw interactions table...")
# Extract dataframes
interactions_df = all_dataframes.get('interactions', pd.DataFrame())
conversations_df = all_dataframes.get('conversations', pd.DataFrame())
plugin_calls_df = all_dataframes.get('plugin-calls', pd.DataFrame())
plugin_resources_df = all_dataframes.get('plugin-resources', pd.DataFrame())
users_df = all_dataframes.get('users', pd.DataFrame())
if interactions_df.empty:
logging.error("No interactions data available")
return pd.DataFrame()
# Filter for user-led interactions only
user_interactions = interactions_df[interactions_df['actor'] == 'user'].copy()
if user_interactions.empty:
logging.warning("No user interactions found")
return pd.DataFrame()
logging.info(f"Processing {len(user_interactions)} user interactions...")
# Initialize the raw interactions table
raw_interactions = pd.DataFrame()
# Base columns from interactions
raw_interactions['Timestamp'] = user_interactions['created_time']
raw_interactions['Conversation ID'] = user_interactions['conversation_id']
raw_interactions['Interaction ID'] = user_interactions['id']
raw_interactions['Interaction Type'] = user_interactions['type'] # Changed from 'interaction_type'
# Get conversation domain from conversations table
if not conversations_df.empty:
conversation_domain_map = conversations_df.set_index('id')['primary_domain'].to_dict() # Changed from 'domain'
raw_interactions['Conversation Domain'] = raw_interactions['Conversation ID'].map(conversation_domain_map)
else:
raw_interactions['Conversation Domain'] = ""
# Get conversation topics (aggregated for each conversation)
logging.info("Processing conversation entities...")
raw_interactions['Conversation Topic'] = raw_interactions['Conversation ID'].apply(
lambda x: get_conversation_topics(interactions_df, x)
)
# Get interaction content and bot response
logging.info("Processing interaction content and bot responses...")
raw_interactions['Interaction Content'] = user_interactions.apply(
lambda row: get_interaction_content(row, interactions_df), axis=1
)
raw_interactions['Bot Response'] = user_interactions.apply(
lambda row: get_bot_response(row, interactions_df), axis=1
)
# Get plugin information
logging.info("Processing plugin information...")
raw_interactions['Unsuccessful Plugins'] = raw_interactions['Interaction ID'].apply(
lambda x: get_plugin_info(x, plugin_calls_df, 'unsuccessful')
)
raw_interactions['Plugin Served'] = raw_interactions['Interaction ID'].apply(
lambda x: get_plugin_info(x, plugin_calls_df, 'served')
)
raw_interactions['Plugin Used'] = raw_interactions['Interaction ID'].apply(
lambda x: get_plugin_info(x, plugin_calls_df, 'used')
)
# Get resource information
logging.info("Processing resource information...")
raw_interactions['Resource Domain'] = raw_interactions['Interaction ID'].apply(
lambda x: get_resource_info(x, plugin_resources_df, 'domain')
)
raw_interactions['No of Citations'] = raw_interactions['Interaction ID'].apply(
lambda x: get_resource_info(x, plugin_resources_df, 'citation_count')
)
raw_interactions['Content Item Name'] = raw_interactions['Interaction ID'].apply(
lambda x: get_resource_info(x, plugin_resources_df, 'content_item_name')
)
raw_interactions['Content Item ID'] = raw_interactions['Interaction ID'].apply(
lambda x: get_resource_info(x, plugin_resources_df, 'content_item_id')
)
raw_interactions['Ticket Type'] = raw_interactions['Interaction ID'].apply(
lambda x: get_resource_info(x, plugin_resources_df, 'ticket_type')
)
raw_interactions['Ticket ID'] = raw_interactions['Interaction ID'].apply(
lambda x: get_resource_info(x, plugin_resources_df, 'ticket_id')
)
# Get interaction surface
raw_interactions['Interaction Surface'] = raw_interactions['Interaction ID'].apply(
lambda x: get_interaction_surface(x, interactions_df)
)
# Get user information
if 'user_id' in user_interactions.columns:
logging.info("Processing user information...")
raw_interactions['User Preferred Language'] = user_interactions['user_id'].apply(
lambda x: get_user_language(x, users_df)
)
else:
raw_interactions['User Preferred Language'] = ""
# Add placeholder columns for external user data
raw_interactions['User Department'] = "" # To be populated from external identity system
raw_interactions['User Location'] = "" # To be populated from external identity system
raw_interactions['User Country'] = "" # To be populated from external identity system
logging.info(f"Raw interactions table built with {len(raw_interactions)} rows and {len(raw_interactions.columns)} columns")
return raw_interactions
def main():
"""Main function to orchestrate the entire process"""
# Get user input for date range
time_filter, start_date_str, end_date_str = get_user_date_inputs()
logging.info("Starting raw interactions table builder...")
# Step 1: Fetch all data
all_dataframes = {}
for endpoint in ENDPOINTS:
df = fetch_data(endpoint, time_filter)
if not df.empty:
all_dataframes[endpoint] = df
if not all_dataframes:
logging.error("No data retrieved from any endpoint")
return
# Step 2: Build raw interactions table
raw_interactions_table = build_raw_interactions_table(all_dataframes)
if raw_interactions_table.empty:
logging.error("Failed to build raw interactions table")
return
# Step 3: Save results
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# Save raw data to Excel (optional)
raw_data_file = Path(f"moveworks_raw_data_{start_date_str}_to_{end_date_str}_{timestamp}.xlsx")
with pd.ExcelWriter(raw_data_file, engine='openynxl') as writer:
for endpoint, df in all_dataframes.items():
sheet_name = endpoint[:31] # Excel sheet name max limit
df.to_excel(writer, sheet_name=sheet_name, index=False)
logging.info(f"Raw data saved to {raw_data_file}")
# Save final raw interactions table
final_file = Path(f"raw_interactions_table_{start_date_str}_to_{end_date_str}_{timestamp}.xlsx")
raw_interactions_table.to_excel(final_file, index=False, sheet_name='Raw Interactions')
logging.info(f"Final raw interactions table saved to {final_file}")
# Also save as CSV for easier processing
csv_file = Path(f"raw_interactions_table_{start_date_str}_to_{end_date_str}_{timestamp}.csv")
raw_interactions_table.to_csv(csv_file, index=False)
logging.info(f"Final raw interactions table saved to {csv_file}")
# Print summary
print("\n" + "="*50)
print("RAW INTERACTIONS TABLE SUMMARY")
print("="*50)
print(f"Total interactions processed: {len(raw_interactions_table)}")
print(f"Date range: {start_date_str} to {end_date_str}")
print(f"Time filter: {time_filter}")
print(f"Columns: {list(raw_interactions_table.columns)}")
print(f"Files generated:")
print(f" - {raw_data_file} (raw data)")
print(f" - {final_file} (final table - Excel)")
print(f" - {csv_file} (final table - CSV)")
# Show sample data
if len(raw_interactions_table) > 0:
print(f"\nSample data (first 3 rows):")
print(raw_interactions_table.head(3).to_string())
if __name__ == "__main__":
main()Updated 5 months ago