Content Ingestion Platform
Overview
The Moveworks Content Ingestion Platform enables high-scale ingestion and processing of various articles, pages and files to power our AI Assistant and Enterprise Search experiences. Moveworks customers can use the set of built-in connectors, and even build their own bespoke connectors via the Content Gateway, to enhance the search experience — whether their users are looking for grounded, summarized answers or just trying to find their important documents across the disparate and diverse enterprise systems that their organization uses, the Content Ingestion Platform brings it all together into a single repository.
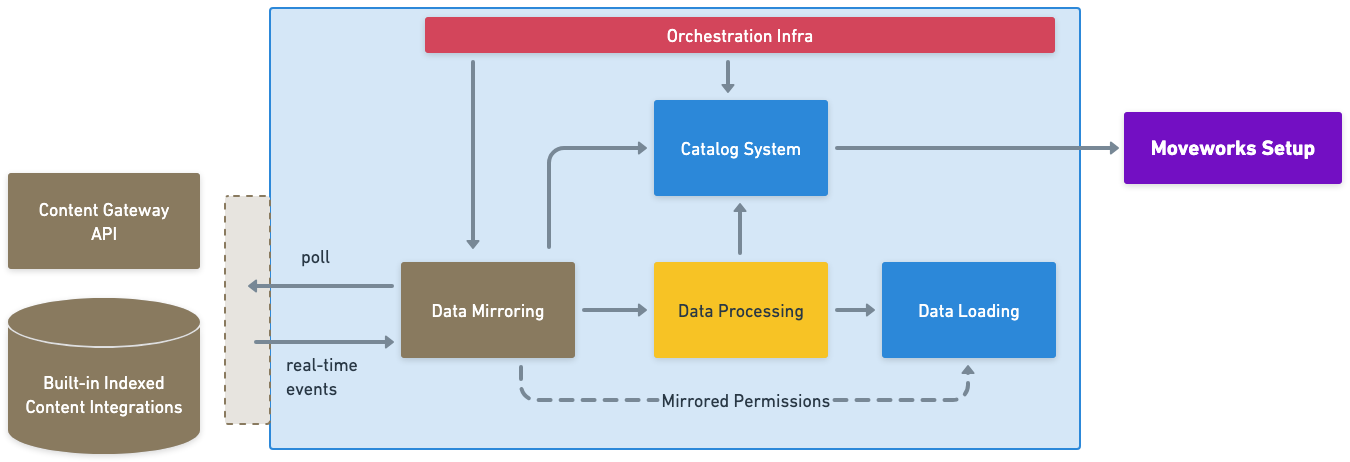
The Content Ingestion Platform is split into 3 main steps:
- Mirroring: Crawls configured source systems to discover all in-scope content and permission records.
- Processing: Applies embeddings and other enrichment (snippetization, NLU, MLS, etc.) on the discovered content.
- Loading: Indexes the processed records into the data store for retrieval.
These steps make it possible for Moveworks to take records from Enterprise systems and serve it to users, with a performant and rich experience. The process is handled by the Orchestration layer (built using Temporal), which schedules and runs the mirroring jobs before streaming information down to the processing and loading stages. You can learn more about the scheduling and types of Mirroring tasks in the next section.
Additionally, the Mirroring and Processing steps write updates to the Catalog System, which allow for customer visibility into the ingestion pipelines via Moveworks Setup.
Mirroring
Mirroring enables Moveworks to discover the content and permissions within the source system and passes the records downstream for processing.
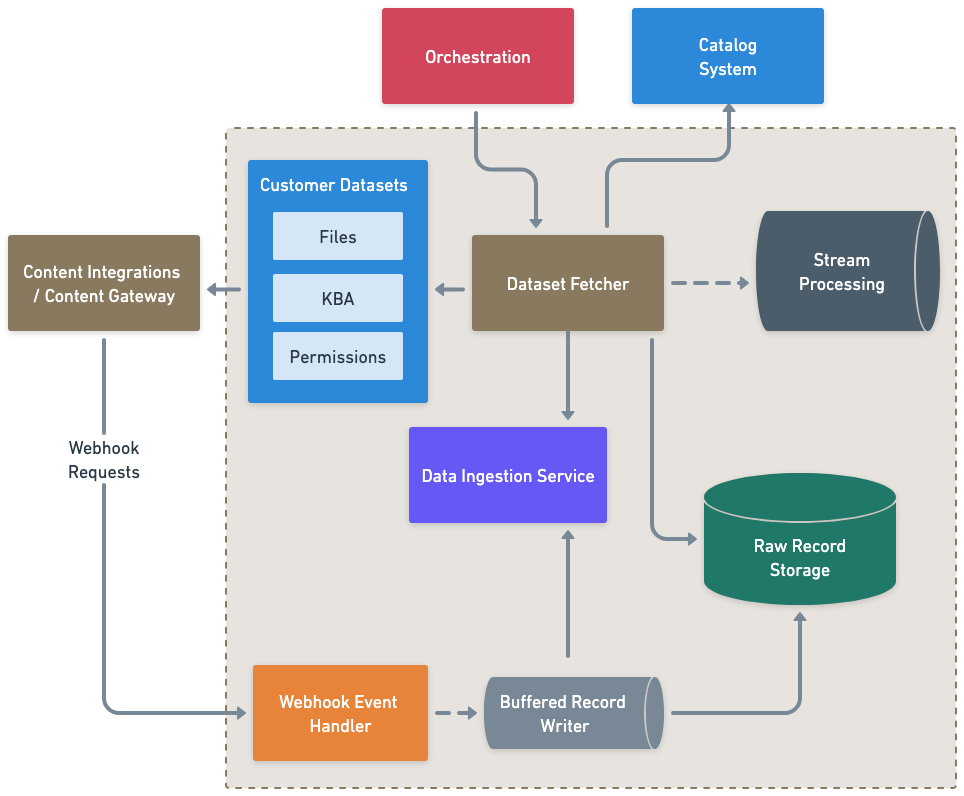
Content Connectors (aka Integrations)
Data Mirroring begins with the configuration of a connector — Moveworks uses a configured connector to manage authentication into a customer’s source system of record. There are broadly two buckets for connectors:
Built-In Connectors
These are first-party integrations that Moveworks builds and maintains for customers to leverage out-of-the-box. You’ll find many of the popular knowledge and content systems are supported natively, and connection can be done self-service through Moveworks Setup. Find the full list of Built-In Connectors.
Content Gateway: Build your own Connectors
Moveworks customers can also build their own Connectors in cases where we do not have a Built-In connector to leverage. This might be appropriate when your organization is using:
- An in-house solution for document storage.
- A legacy system or unsupported version.
- A brand new system that has low market-adoption, or is in a pilot/beta phase.
You can learn more about building connectors for Content Gateway.
Customer Datasets
Once the connector is configured, we also need the actual sync to be configured. This is done by specifying the connector you wish to use, and the details around the ingestion, including:
- The content that is within scope
- How often to ingest the content
- If and how often permissions should be ingested
This information is captured as a Customer Dataset Configuration, which is abstracted within Moveworks Setup (but directly available for Moveworks CS and Support).
Sync Types
For any given system, there are multiple types of syncing that the platform leverages to bring updates into Moveworks. These syncs are parallelized, so we run multiple organization syncs at the same time to allow for higher scale of ingestion.
Full Syncs
By default, Moveworks will do a full sync when the organization is onboarding a new content system for the first time — this will capture all the in-scope content and permissions and create the index to load it in after processing. We continue to run the full sync every day to capture a snapshot of the mirrored records in the case that the index needs to be recreated or evaluated for any reason.
Incremental Sync
Additionally, Moveworks will run incremental syncs multiple times throughout the day (default of every 15 minutes) to capture any changes in the content system, whether new content has been added, permissions or groups have changed, etc. These runs will process and load changes incrementally, unlocking high scale ingestions to be kept in sync much more frequently.
Individual Sync
If the the source system supports webhooks to fire events for changes in content or permissions records, Moveworks will leverage them to pick up individual changes. This allows for updates to the search index in between runs of the incremental sync.
When a sync occurs, the relevant content and permission records are mirrored into Moveworks as a Customer Dataset with individual Records for each associated content or permission record.
Completing Mirroring
Once the Customer Dataset Records are assembled, the platform performs validations to ensure that there are no major errors or gaps in the collected data.
The Customer Dataset Records go to two different places:
- Streamed for Processing
- Stored as Raw Records, used in cases where the index needs to be reconstructed or if we are testing changes to Mirroring and do not want to push the test records downstream (AWS S3)
- Raw records are protected via AWS KMS to org specific buckets, to ensure that that is no leakage or access outside of authorized Movesters who can request temporary, audited access for troubleshooting and/or debugging.
Information and metadata related to the mirroring syncs are also pushed to the Catalog System to allow for observability tooling to keep customers updated on the status of the runs.
Processing
Customer Dataset Records that are streamed to Kafka end up in a central bucket from which distributed, parallel processes will pick up individual records and enrich them before loading into the customer’s index.
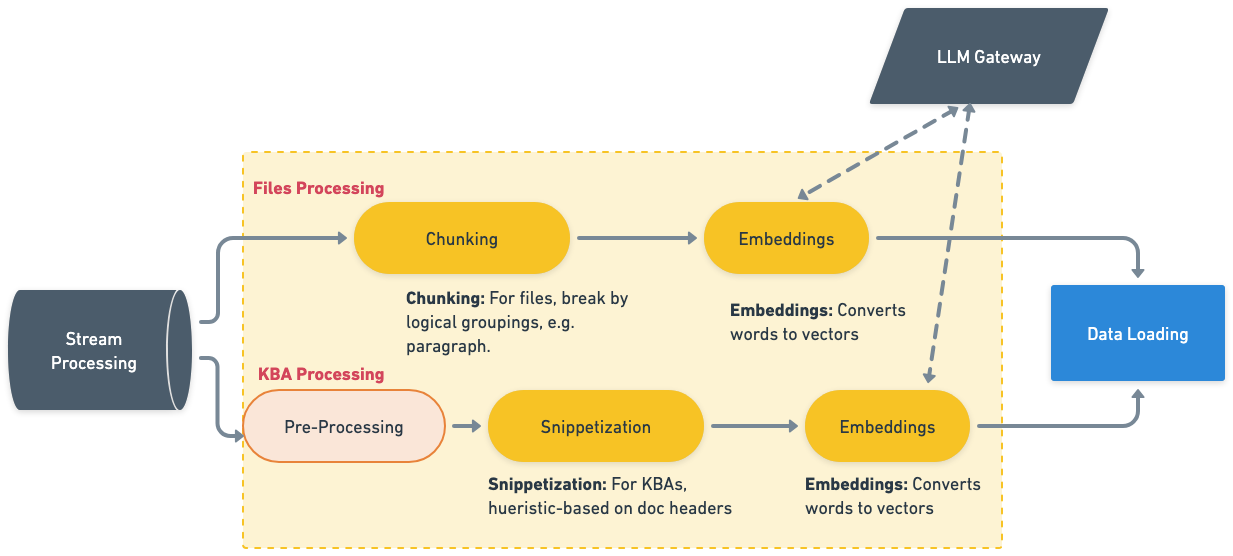
Steps
Currently, processing has slightly different snippetization/chunking and embeddings strategies based on the MIME type of the content:
- Knowledge Base Articles (KBA): HTML-content such as .aspx pages & .md/.mdx (markdown)
- Files: Such as .pdf, .ppt, .doc, & .txt
Snippetization / Chunking
This step involves breaking the text content of the document into multiple pieces for better retrieval and ranking performance once embedding is complete. Documents will either be broken into snippets or chunks, which are splits based on paragraphs, header types, or even semantic groupings. Even within agentic RAG setup, breaking down docs into relevant chunk provides a more precise retrieval experience.
Enrichment
Further enrichment may be done to enhance the performance of the snippets and chunks — this is an active area of development but could include areas such as:
- File Summaries
- Metadata
- Activity (views, access, shares)
This information can be included as part of the embeddings for the record to influence greater rank and retrieval performance.
Embedding
Once the necessary snippets/chunks and enrichment have been determined, the output is sent to the Embeddings Model to create a vector representation of the data. This is what is ultimately passed off to the index, via the Loading step, and used for highly efficient, relevance search.
Loading
Once processing is complete, the embedded Customer Dataset Records are passed into the customer index for the Loading phase.
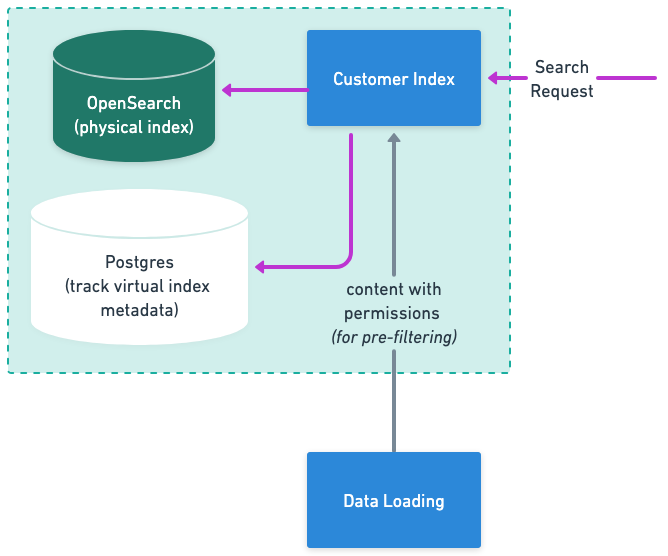
The Loading phase stores data in a few ways:
- Customer Index: “Hot” store of the indices that is updated on every sync type.
- Physical Index (OpenSearch): “Cold” store of all the document and chunk indices, updated on full syncs.
- Metadata (Postgres): Information related to the virtual indices is stored here such the time stamps of the syncs etc.
Each customer organization has two live content indices:
{org}-file-index- For content that was processed as Files.{org}-kb-index- For content that was processed as KBAs.
There is also a permissions platform, which you can read more here. Once loaded, the content is ready for retrieval via Enterprise Search.
Updated 8 months ago