Response Sizes
What is the maximum response size?
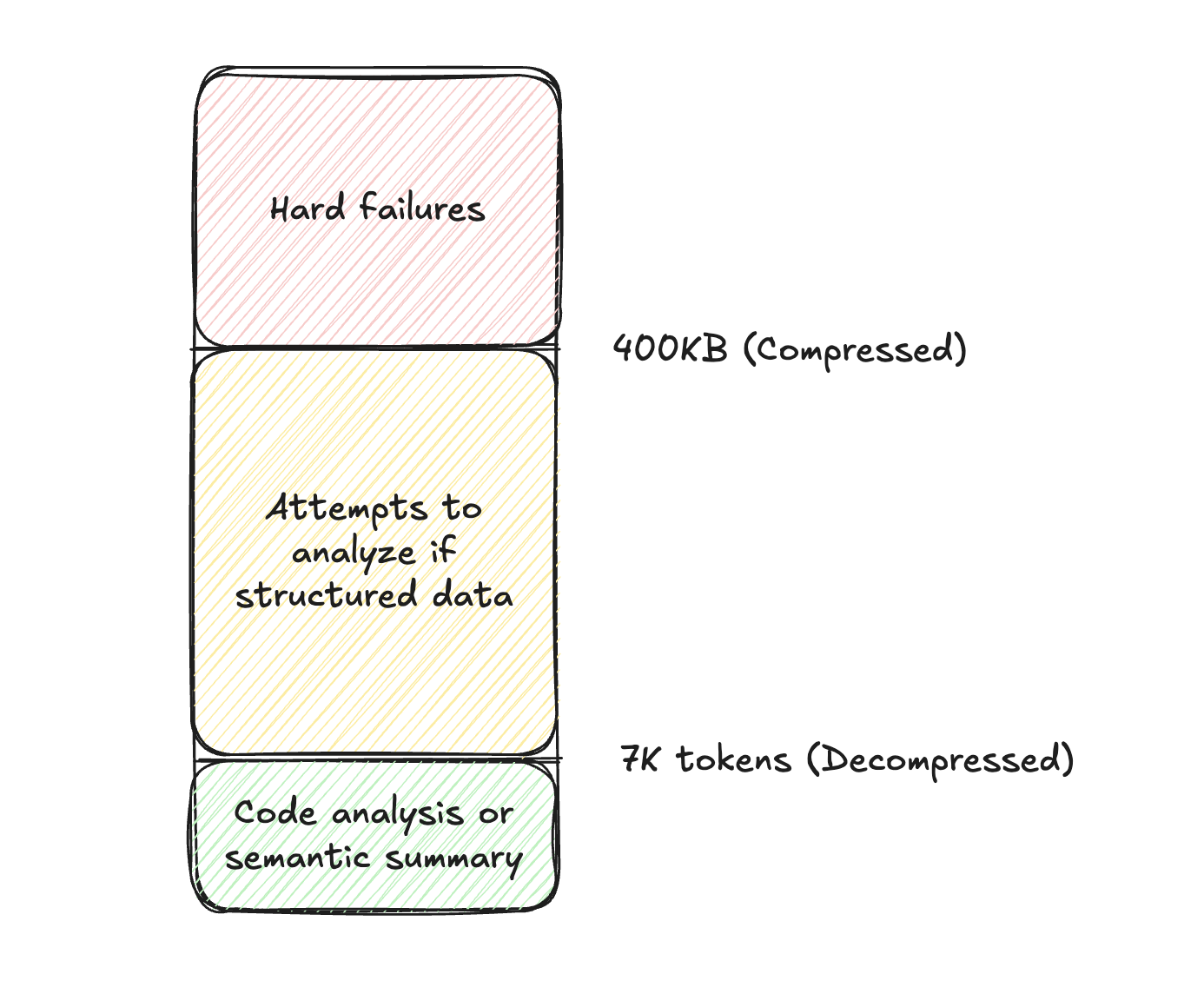
There are two limits to keep in mind: 400KB and 7k tokens.
- 400KB is the limit of the amount of compressed data which can be returned to the Reasoning Engine’s Working Memory. Moveworks manages the compression for you. For reference, a 10 column, 30k row CSV with a mix of string and numeric columns is ~3MB, but compresses to ~400KB. If the size of the data after Moveworks compression is >400KB, it will result in a hard failure of the plugin.
- 7k tokens (~28kB) is the limit for the amount of information we can semantically summarize. If the Reasoning Engine runs into this limit, it will inform the user that there is too much data.
If there is too much data, the Reasoning Engine will attempt to use its Code Interpreter to analyze data. This is only possible if your plugin response does not contain semi-structured data.
What are tokens?
Tokens are the basic units of input and output in a Large Language Model. It can be a word, part of a word, a character, or more.
To approximate the number of the tokens in your plugin response, you can use this helpful tokenizer tool from OpenAI: https://platform.openai.com/tokenizer
Recommendations
If you're building a plugin that will return a lot of data, we recommend the following.
Plugin Selection
-
Describe the response schema: Always mention all fields from the returned data in the plugin description.
- ❌ GetSalesforceCustomers: returns data from customers in Salesforce.
- ✅ GetSalesforceCustomers: returns account name, owner, and renewal data for customers in Salesforce.
This will ensure more reliable plugin selection for all the different use cases the data may support.
-
One plugin, one data source: Multiple overlapping plugins on the same dataset can create inconsistent experiences.
- ❌ GetOpenAccountsPlugin, GetEnterpriseAccountsPlugin, GetProspectAccountsPlugin
- ✅ GetSalesforceAccountsPlugin, GetSalesforceOpportunitiesPlugin
Response Structure
- Use friendly names. Drop the business system default names, and rename fields to friendly, intuitive names that are easy for the model to understand. This will also make the data more friendly when it is exposed back to the user in a message, citation, or future medium.
- Flatten your data. When possible, flatten your data into tabular fields, avoiding a nested JSON structure. This makes the data easier to work with resulting in higher model reliability.
- Bad Example
{ "people": [ { "name": "John Doe", "details": { "age": 30, "city": "New York" } }, { "name": "Anna Smith", "details": { "age": 25, "city": "London" } }, ] } - Good Example
{ "people": [ { "name": "John Doe", "age": 30, "city": "New York" }, { "name": "Anna Smith", "age": 25, "city": "London" } ] }
- Bad Example
UX Recommendations
- Disable the Activity Confirmation Policy. Given the goal is to simply fetch data, unless it is computationally expensive or you have tight rate limits, we don't recommend getting user confirmation first. This creates needless friction for your users.
- Add a URL field. This allows the model to link the specific business system record in the response.
LinkToAccount: "$CONCAT(['https://moveworks.lightning.force.com/lightning/r/Account/", item.Id, "/view"], "") - Avoid Analysis Instructions. Unless you see plugin-specific behavior that is not intended, avoid adding instructions about how the model should analyze data (e.g. "please fuzzy match
TelecamtoTelecom"). This will likely be ignored and could negatively impact performance. - Configure Citations: if you want business records to be cited, you need to add
idorfriendly_idso that each record can be individually cited (instructions).
Reducing the original size
If you're still running into issues with the size of your plugin response, consider the following
- Schema Pruning. Eliminate fields from a data structure using the MERGE statement from our Data Mapper.
- Attribute Compression. Reduce the length of a text field using the summarize text action
- Record Filtering. Remove records from your list.
- Pre-filtering. You can collect slots or use meta info to reduce the number of records you fetch from an external system.
- Retrieve time series between a
start_date&end_date - Constrain records that are
assigned_tothe current user - Fetch records where a numeric attribute is greater than some value (e.g. accounts above 500 users)
You can define multiple of these inputs on the same plugin & mark the inputs as optional.
- Retrieve time series between a
- Post-filtering. If the system doesn't support API-based filtering, you can also filter the data inside your plugin's process with DSL FILTER expressions
- Pre-filtering. You can collect slots or use meta info to reduce the number of records you fetch from an external system.
Updated 10 days ago