Reasoning Loops
As we discussed in the article on the Moveworks Agentic Architecture, the AI Assistant has a structured approach to exploring the range of solutions available to offer to the user for every request, and the combination of three reasoning loops is used to accomplish that:
- Internal planning iteration loop to identify the most useful course of action
- Internal execution iteration loop to execute the plan step-by-step and assess what to do next at each stage
- User-facing feedback loop to communicate the thought process, seek confirmation and utilize user feedback to take the next step
Planning iteration loop
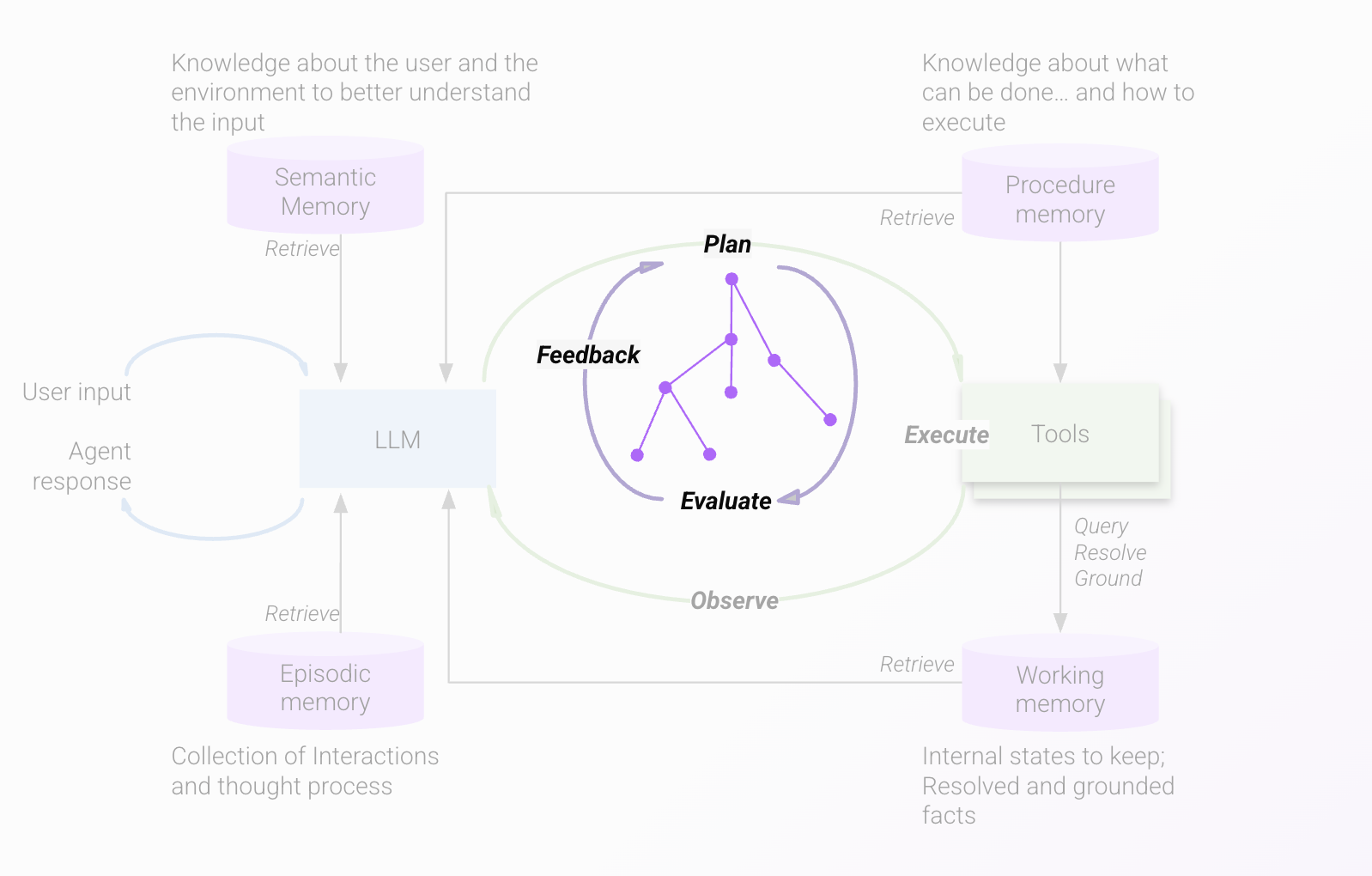
The innermost of the three loops, it consists of a planning and evaluating module that is set into motion by the user’s query. The planner uses an LLM call to create the plan to serve the user’s request, by going through the list of all available tools for the user in the environment. This plan is evaluated by another LLM called the plan evaluator that assesses whether the plan addresses the user’s need, and if it identifies a gap, it provides that feedback to the planner, which incorporates it to create a new plan.
These planning cycles result in a final plan that is then provided to the next reasoning loop, called the execution iteration loop.
Execution iteration loop
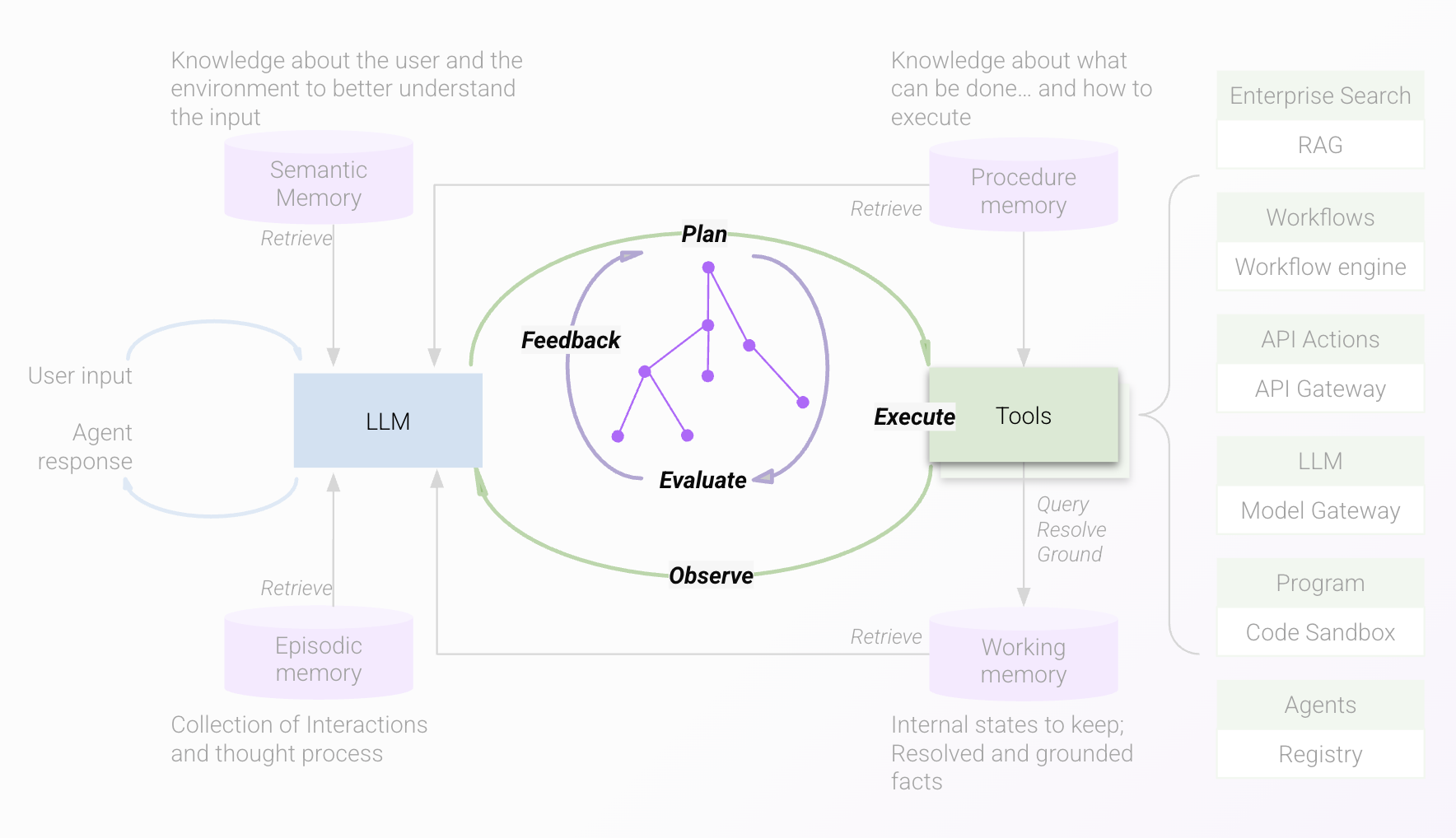
This loop is responsible for taking the plan devised in planning iteration and executing it by calling tools which are specialized components that perform a variety of tasks such as performing search, executing workflows, calling APIs, running code, calling LLMs for tasks such as summarization, and many more.
The reasoning engine observes the outcome of executing the step, which could be a successful completion and output returned by a search or workflow plugin, or an error which may indicate an invalid operation, missing required information, or a request by a plugin to seek user confirmation.
These outcomes are sent to the agentic reasoning LLM, which then determines whether it is independently able to proceed with information available to it in the conversation or user context (semantic or episodic memory - see the Memory Constructs knowledge article for details), or whether it needs to seek user feedback. In all cases, the reasoning LLM provides the user with updates on the steps it is taking.
User-facing feedback loop
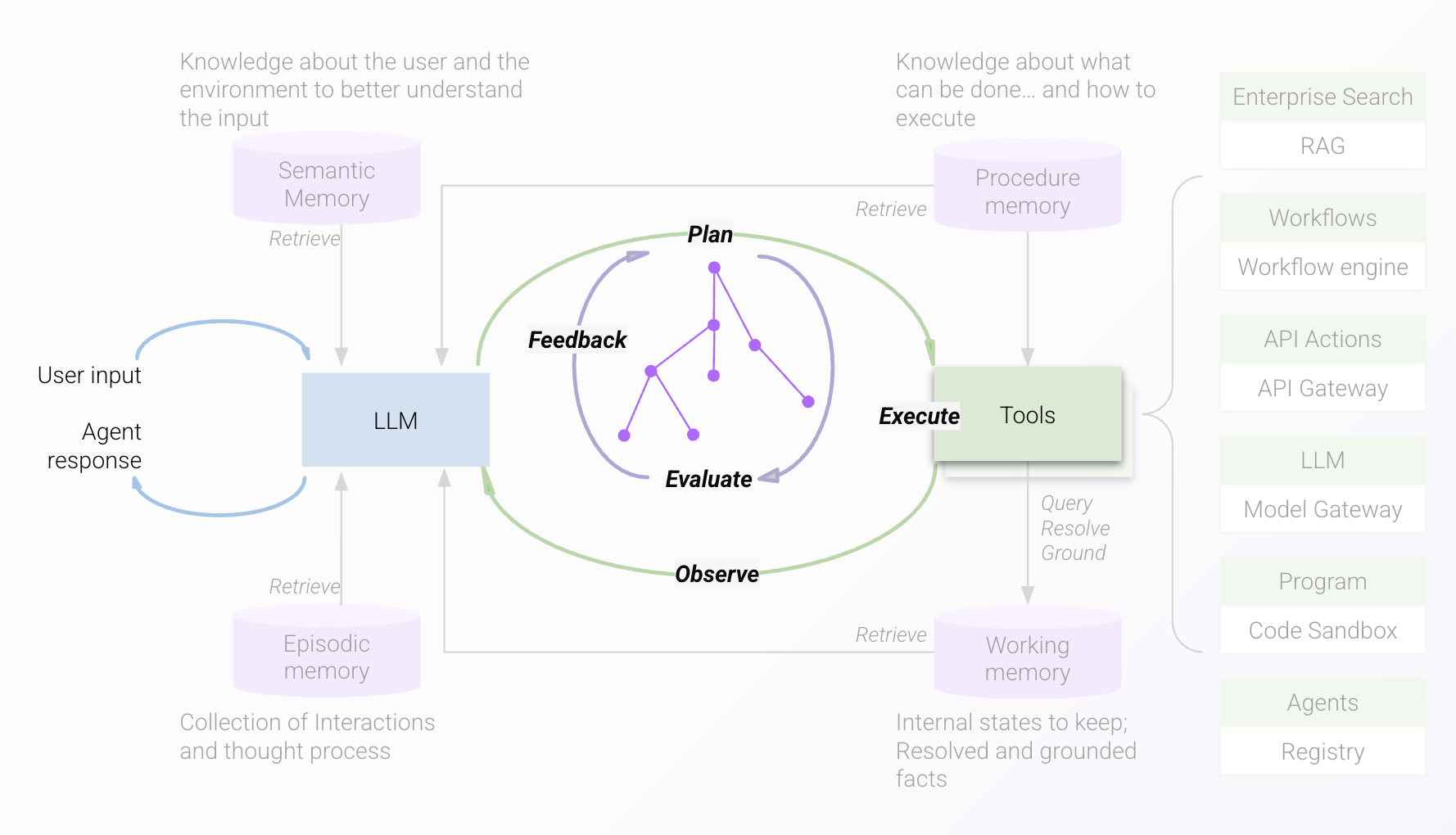
This is the step where two things may occur:
- If the agentic reasoning LLM determines that user input is needed to take the next step, the user is prompted for confirmation or feedback or required information
- The user may initiate a new request or a follow-on request to the previous one, setting in motion the cycle of planning iteration and execution iteration all over again.
Read more about the architecture here.