Data API : How to calculate top metrics
Data API : How to calculate top metrics
Overview
This document provides calculation methods for key performance metrics using the Moveworks Data API. All calculations are based on the Beta2 version of the API and use the actual response structures from the Moveworks platform.
API Endpoints
The Moveworks Data API provides five main endpoints:
- Conversations:
https://api.moveworks.ai/export/v1/records/conversations - Interactions:
https://api.moveworks.ai/export/v1/records/interactions - Plugin Calls:
https://api.moveworks.ai/export/v1/records/plugin-calls - Plugin Resources:
https://api.moveworks.ai/export/v1/records/plugin-resources - Users:
https://api.moveworks.ai/export/v1/records/users
Data Structure
The API returns data in OData JSON format:
Data Hierarchy
- Conversations (parent) → Interactions (1-to-many)
- Interactions → Plugin Calls (1-to-many)
- Plugin Calls → Plugin Resources (1-to-many)
- Users (standalone table) → All tables contain User ID which can be used to lookup data from this table.
Please note: The following section refers to data tables such as Conversations, Interactions, and Plugin-calls. This assumes that you have already fetched the data from the API and stored it in your data lake.
Metric Calculations
Adoption Metrics
Active Users
Active users are defined as users who perform at least one interaction within a given timeframe.
Method 1 (Interactions-based):
- Fetch all interactions in the timeframe.
- Count distinct values of the
user_idfield.
Method 2 (Users table-based):
- Query the users table.
- Count users where
latest_interaction_timefalls within the timeframe.
User Adoption Over Time
Shows the adoption trend of the AI Assistant over time.
- Identify all unique users with interactions in the timeframe.
- Retrieve all users with
access_to_bot = truefrom the users table. - Plot the unique active users against the baseline (total users with access to the AI Assistant).
User Retention Over Time
Tracks the percentage of users who return to the AI Assistant within a defined time window.
- Extract unique
user_idvalues from the interactions table. - If the same
user_idappears more than once in the timeframe, mark that user as retained.
New Users
New users are those who interact with the AI Assistant for the first time within the selected timeframe.
- Count users from the users table where
first_interaction_timefalls within the timeframe from the users table. - To find single-interaction users, count users where
first_interaction_time = latest_interaction_time.
Conversation Metrics
Total Conversations (excluding notifications)
- Count all distinct
idvalues from the conversations API in the timeframe.
Conversations by Route
- Fetch unique conversation IDs from the conversations table.
- Group them by the
routeattribute.
Conversations by Domain
- Fetch unique conversation IDs from the conversations table.
- Group them by the
primary_domainattribute.
Conversation Topics
Conversation topics are aggregated from interaction-level topic detection.
- Filter interactions where
type = INTERACTION_TYPE_FREE_TEXTin the interactions table. - Group
detail.entityvalues by conversation ID.
Interaction Metrics
User Feedback
End users can provide feedback via thumbs clicks or feedback forms.
👍 👎 Clicks
- Captured as type =
INTERACTION_TYPE_INTERNAL_LINKin the interactions table. - Identified using
detail.resource_id:Helpful→ Thumbs UpUnhelpful→ Thumbs Down
Feedback form submissions
- Captured as type =
INTERACTION_TYPE_UIFORM_SUBMISSION. - The
labelattribute indicates a feedback form. - The feedback type (Helpful/Unhelpful) is stored in
detail.detail. - Free-text input is captured in
detail.content.
Live agent transfers
The end users can escalate their issues to live agent if they find the summarized response provided the AI Assistant as not helpful or request to connect with an agent directly.
Plugin calls table
- In either cases if the end user is connected with a live agent it will be captured in the plugin-calls table. Search for the
nameas “Start Live Agent Chat” plugin. - To find the successful cases where the end user was placed in the queue the served and used will be
true. - Capture the conversation and interaction id. To fetch the interaction details use the
interaction_idattribute and fetch the details from the interactions table.
Interactions table
The interaction table will also capture if a end user has requested to connect with the live agent. There are two methods - Either go through the handoff or requesting to connect directly
- In either cases the end user is presented with form to be submitted when they want to connect.
- Filter for interaction based on the type =
INTERACTION_TYPE_UIFORM_SUBMISSISIONand label =handofformw_form - The detail.detail attribute will contain the form name will contain
Live Agent chat request. However if you have configured a separate Rich Ticket Filing form - The form name will reflect the field called asField Title
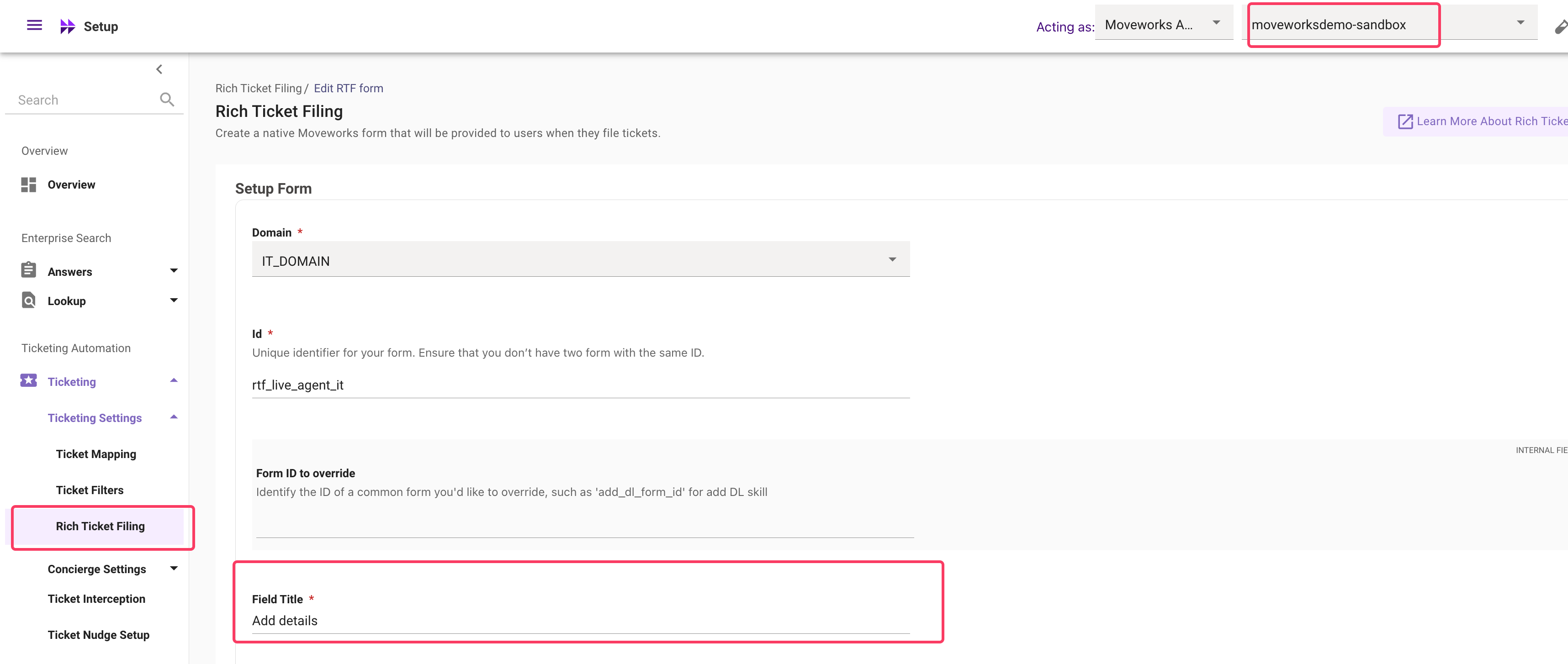
Create Ticket interaction
End users can file a ticket related to their issue if they do not find the AI Assistant as helpful. Similar to the above live agent request this can be tracked both via the plugin calls table and the interactions table.
Plugin calls table
- In either cases if the end user is connected with a live agent it will be captured in the plugin-calls table. Search for the
nameas “Create Ticket” plugin. - To find the successful cases where the end user was placed in the queue the served and used will be
true. - Capture the conversation and interaction id. To fetch the interaction details use the
interaction_idattribute and fetch the details from the interactions table.
Interactions table
- In either cases the end user is presented with form to be submitted when they want to connect.
- Filter for interaction based on the type =
INTERACTION_TYPE_UIFORM_SUBMISSISIONand label =handofformw_form - The detail.detail attribute will contain the form name will contain
File IT Ticket. However if you have configured a separate Rich Ticket Filing form - The form name will reflect the value in field called asField Title
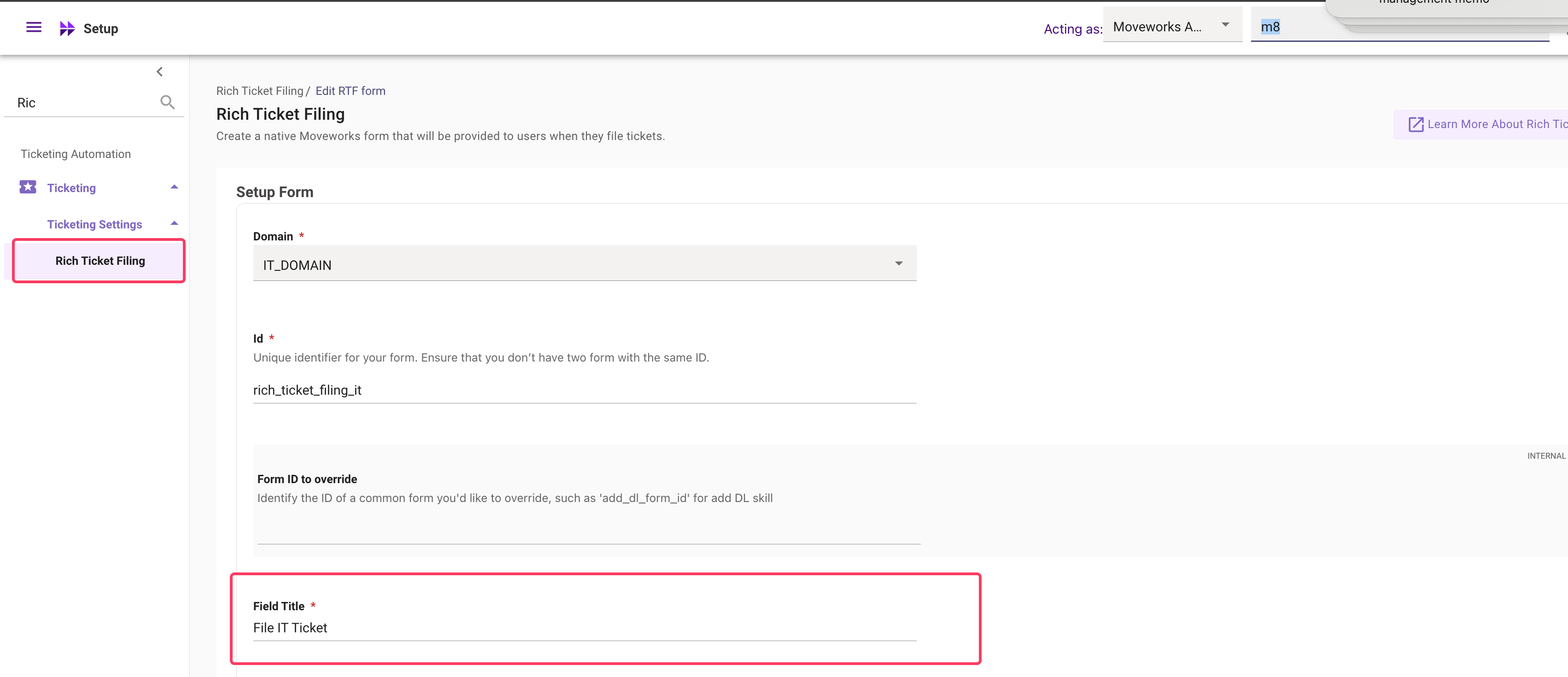
Notification metrics
Total notifications sent
- Query
conversationstable: All conversations whereroute= “Notification”
Total engaged notifications
- Query
conversationstable: Get all conversation IDs whereroute= “Notification”. - Lookup all conversation IDs in the
Interactionstable whereactor= user
This gives you all conversations that were engaged by the user.
Please note : Every notification will have a unique conversation ID.
Breakdown of notifications by their type
- Query
conversationstable: All conversations whereroute= “Notification” - Use the
typefield for getting the breakdown of notifications by their type.
Top engaged notification types
- Query
conversationstable: Get all conversation IDs whereroute= “Notification”. - Lookup all conversation IDs in the
Interactionstable whereactor= user
This gives you all conversations that were engaged by the user.
You can then breakdown these notifications by using the type field in the conversations table.
CSAT metrics
CSAT (Customer Satisfaction) data is exposed via the Data API as a specific notification conversation type, plus the user’s responses captured in the Interactions entity. The sections below cover what is provided in the CSAT data and the most common CSAT calculations.
What’s provided in the CSAT data
CSAT data is split across two entities — a conversation row that represents the survey being sent, and a set of interaction rows that represent what the user did with it. There is no separate “CSAT” table; everything you need is reachable from the standard conversations and interactions entities.
CSAT conversation type
Every CSAT survey sent to a user appears as a unique row in the conversations table. Identify CSAT surveys by:
route = "Notification"type = "CONVERSATION_TYPE_CSAT_NOTIFICATION"
Key fields on a CSAT conversation row:
A row in conversations with the filters above represents delivery of a CSAT survey. The user’s response (or non-response) lives in the interactions table.
CSAT interactions
When a user interacts with a CSAT survey, one or more rows are written to the interactions table with the same conversation_id as the survey. There are two interaction shapes you should know about:
1. Star rating (button click)
The 1–5 star rating the user selects is captured as a button click.
Users can re-rate the same survey. Each click writes a new row, so multiple INTERACTION_TYPE_BUTTON_CLICK rows can share the same conversation_id. To get the final rating per user, take the latest row by created_time per conversation_id.
2. Free-text feedback (form submission)
If the user leaves a written comment alongside their rating, it is captured as a UI form submission.
Both rating and free-text feedback rows can be joined back to the originating CSAT conversation via conversation_id, and to the user via user_id.
A CSAT conversation with no matching actor = "user" rows in the interactions table represents a survey that was delivered but not engaged with. Use this to compute response rate (see below).
Total CSAT surveys sent
Counts every CSAT survey delivered to an end user in the timeframe.
- Query the
conversationstable. - Filter where
route = "Notification"andtype = "CONVERSATION_TYPE_CSAT_NOTIFICATION". - Count distinct
idvalues.
Each CSAT survey is a unique conversation. Sent volume is driven by survey eligibility (active users not surveyed in the last 180 days) and the configured sampling rate.
CSAT response rate
The percentage of delivered CSAT surveys that the user actually responded to (rated and/or commented).
- Sent: Get all conversation IDs from the
conversationstable whereroute = "Notification"andtype = "CONVERSATION_TYPE_CSAT_NOTIFICATION". - Engaged: From the
interactionstable, find rows whoseconversation_idis in the set above andactor = "user". Count distinctconversation_idvalues. - Response rate = engaged / sent.
CSAT score distribution
Breaks down CSAT responses by the 1–5 star rating the user selected.
- Get all conversation IDs where
route = "Notification"andtype = "CONVERSATION_TYPE_CSAT_NOTIFICATION"from theconversationstable. - From the
interactionstable, filter for rows whoseconversation_idis in that set andtype = "INTERACTION_TYPE_BUTTON_CLICK". - The selected rating is in
detail.content(the button name corresponding to the star rating). - Group by
detail.contentto get the distribution.
Users can re-rate the same CSAT survey. If you want only the final rating per user, take the latest interaction (by created_time) per conversation_id.
CSAT free-text feedback
Ingests the qualitative comments users leave alongside their rating.
- Filter the
interactionstable where:type = "INTERACTION_TYPE_UIFORM_SUBMISSION"label = "mw_form"detail.detail = "CSAT Feedback"
- The user’s comment is in
detail.content. - Join back to
conversationsonconversation_idto attribute the comment to the originating CSAT survey, and confirmtype = "CONVERSATION_TYPE_CSAT_NOTIFICATION"if you want to exclude any free-text feedback that wasn’t from a CSAT campaign.
Plugin call metrics
Plugin success rate
The success of a plugin can be measured by evaluating when it was served and used, and comparing those outcomes against user feedback. You can measure this for a specific plugin or a list of plugin based on your requirement.
- Filter plugin calls
- Query the
plugin-callstable using the plugin’snameattribute.
- Query the
- Identify served and used cases
- Select all scenarios where:
served = trueused = true
- Select all scenarios where:
- Retrieve interaction IDs
- For each matching plugin call, capture the
interaction_idattribute.
- For each matching plugin call, capture the
- Attribute feedback
- Query interactions where:
type = INTERACTION_TYPE_UIFORM_SUBMISSIONlabel = feedback
- Match the
parent_interaction_idagainst the interaction IDs from Step 3. - If a match exists, attribute that feedback to the plugin interaction.
- Query interactions where:
- Mark success or failure
- If the feedback is Helpful, mark the plugin call as a success.
- If the feedback is Unhelpful, mark it as a failure.
- ⚠️ If feedback coverage is very low, handleno-feedback cases**** according to your reporting requirements (e.g., exclude, assume neutral, or distribute proportionally).
Knowledge gaps
A knowledge gap is considered when Knowledge base plugin is called but it is Unsuccessful (Served = false & Used = false)
- Filter plugin calls
name= “Knowledge Base”served= false andused= false
- Capture the interaction ID and find those in the interaction table based on the
idcolumn. - The user message will be present in the
detail.contentattribute and the detected topic will be present under thedetail.entityattribute.
*The knowledge gap referenced here is prescriptive - You can adapt this to your own definition
Approvals processed
To fetch the approvals processed via the AI Assistant search for plugin name as ‘Update Approval Record’ plugin and Served = true and Used = true.
- Filter plugin calls
name= “Update Approval Record”served= true andused= true
- Capture the plugin call id from the
idattribute - Go through the plugin resource table and find all of the approval resources processed through that specific plugin call. Filter on
plugin_call_idand enter the id’s fetched from the above step.
Agent studio plugin reporting
If you built custom plugin or installed plugins from marketplace - These are included in the Data API details. The custom plugin will be referred in the plugin-calls table.
- Filter for the plugin call instance containing custom plugin name based on
nameattribute.
To find the custom plugin name open to the Agent studio app and go through the plugins listed there.
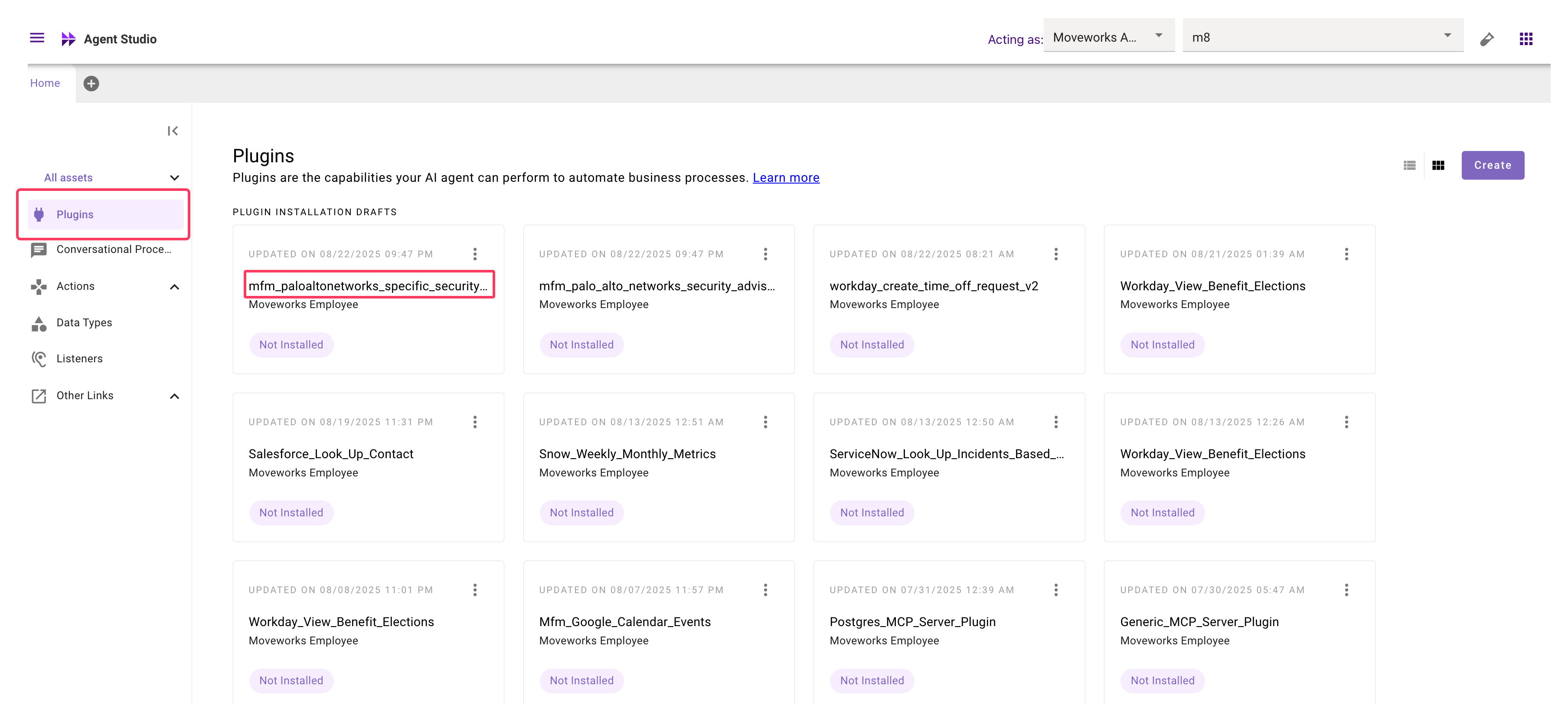
Value Metrics
These are prescriptive definitions. Please feel free to modify the calculations as per your own requirements.
Deflections / Resolutions
Definition: Deflections are interactions where no ticket was filed, no live agent connection was requested, and no negative feedback was given by the end user.
Steps
- Fetch free-text interactions
- Filter all interactions where
type = INTERACTION_TYPE_FREE_TEXTand capture theidvalues.
- Filter all interactions where
- Identify ticket filing cases
- Filter for interactions where:
type = INTERACTION_TYPE_UIFORM_SUBMISSIONlabel = "handoff"or"mw_form"detail.detail = "File IT Ticket"(adjust based on your ticketing form name).
- Filter for interactions where:
- Identify live agent handoffs
- Filter for interactions where:
type = INTERACTION_TYPE_UIFORM_SUBMISSIONlabel = "handoff"or"mw_form"detail.detail = "Live Agent chat request"(adjust based on your form name).
- Filter for interactions where:
- Identify negative feedback
- Filter for interactions where:
type = INTERACTION_TYPE_UIFORM_SUBMISSIONlabel = "feedback"detail.resource_id = "Unhelpful".
- Filter for interactions where:
- Match signals to free-text interactions
- Use the
parent_interaction_idfrom steps 2, 3, and 4. - If a match is found with a free-text interaction, assign the signal accordingly.
- Use the
- Count deflections
- Remaining interactions (without a ticket, handoff, or negative feedback) are deflected interactions.
Time Savings
Definition: Time savings are calculated based on the hours saved when specific requests are automated by the AI Assistant.
Requirements
- Estimated hours saved for each automated request.
- Personas for which you want to calculate hours saved.
Example: Software Requests
- Filter plugin calls
- Select plugin calls where
name = "Grant Software Access". - Only include cases where
served = trueandused = true.
- Select plugin calls where
- Count successful automations
- Count the number of unique
interaction_idvalues that meet the above criteria.
- Count the number of unique
- Calculate time savings
- Multiply the count by the estimated hours saved per instance.
- This gives the total time saved by automating software requests.
MTTR
Definition:
Mean Time to Resolution (MTTR) is a key metric typically defined by the formula: (Sum of all resolution times)/Total resolutions
In the world of AI assistants, conversations are often multi-turn, involving several back-and-forth interactions between a user and the bot. Here’s how you can calculate MTTR in this context.
Steps
1. Calculate the Sum of All Resolution Times
- Get user interactions: Retrieve the
interaction_idandcreated_timefor all interactions where theactoris the ‘user’ and thetypeis ‘INTERACTION_TYPE_FREE_TEXT’. - Find corresponding bot responses: For each user interaction, find the matching bot response. Look for interactions where the
actoris the ‘bot’ and theparent_interaction_idmatches the user’sinteraction_idfrom the previous step. Get thecreated_timefor these bot interactions. - Calculate and sum resolution times:
- For each user-bot pair, calculate the resolution time by subtracting the user’s
created_timefrom the bot’screated_time. - Add up all these individual resolution times to get the total sum.
- For each user-bot pair, calculate the resolution time by subtracting the user’s
Optional: Excluding Escalations
The method above counts every bot response as a resolution. To get a more precise metric, you might want to exclude cases that were escalated to a human.
- Find all escalation interactions, such as those with a
typeof ‘INTERACTION_TYPE_UIFORM_SUBMISSION’ where thedetail.detailcontains “Live agent chat request” or “File IT ticket”. - Check the
parent_interaction_idof these escalations. - If an interaction from step 1 is found here, exclude its resolution time from your total sum.
2. Find the Total Number of Resolutions
- To get the denominator for your MTTR calculation, determine the total count of resolutions by following the steps in the official documentation:
3. Calculate the Final MTTR
- Finally, divide the sum of resolution times (from Step 1) by the total number of resolutions (from Step 2) to get your MTTR.